强化学习
贡献者: xzllxls
强化学习(Reinforcement learning)是机器学习的一个领域,主要研究智能主体在环境中应该怎样采取行动以最大化所获得的累积奖励。这类似于心理學行為主義理論关于人类学习行为的相关描述。人类在学习时,也会根据行为效果(也即环境对行为的反馈——奖励或惩罚),来不断调整自己的行为,从而适应环境,以获得最大价值。
强化学习与监督学习和无监督学习一样,都是机器学习的基本范式。但强化学习与监督学习也很大区别。后者在训练学习器时需要带有标记的训练数据。前者在训练模型时,没有做好标记的训练数据,而是须要智能体(agent)产生动作(action)去主动探索环境,环境状态发生改变并给出反馈,产生一个奖励。强化学习的最终目标是尽可能使得奖励最大化。
强化学习的核心问题,包括权衡探索与利用、通过马尔科夫决策理论建立领域的基础、学习延迟强化、构建经验模型以加速学习、利用泛化和层次结构、处理隐藏状态等。
在标准强化学习模型中,智能体主体会与环境产生交互。它可以感知来自环境的信息,也可以产生行为改变环境。
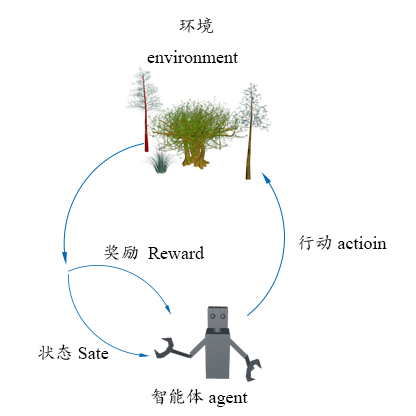
图 1:强化学习基本模型
强化学习的主要方法包括:马尔科夫决策过程、动态规划、时间差分学习等。深度强化学习是现在最广泛使用的强化学习方法。强化学习过程如图 1 所示。
1. 基本概念
- 状态(State):智能体在环境中的状态。通常用 $s$ 表示。
- 状态空间(State space):智能体所有可能的状态的集合。通常用 $S$ 表示。比如,一个智能体有 $n$ 个可能的状态,则状态空间可以记为:$S=\{s_i\}_{i=1}^{n}$。
- 动作(Action):智能体所采取的行为。动作会改变智能体的状态。通常用 $a$ 表示。
- 动作空间(Action space):智能体在某个状态下所能够采取的所有动作的集合。通常用 $A(s)$ 表示。例如,一个智能体在状态 $s_i$ 下有 $n$ 个可选的动作,则其在状态 $s_i$ 下的动作空间可以记为:$A(s_i)=\{a_i\}_{i=1}^{n}$。
- 策略(Policy):指导智能体采取的行为。强化学习的目标就是找到一个好的策略,让智能体按照该策略采取行动,从而完成任务。
- 奖励(Reward):当智能体采取某种动作之后,环境会反馈一个数,其作用是鼓励或者惩罚智能体的行为。该数即称为奖励,通常用 $r$ 表示。奖励是当前状态和当前动作的函数,因此,也可以表示为 $r(s,a)$。通常设置奖励的值为正时,鼓励智能体的行为,奖励值为负数时,惩罚智能体的行为。当然,也可以反过来。奖励可以被人工设计,一个好的奖励设计,有利于强化学习的性能。
- 价值(Value):智能体从当前状态开始,对未来累积总收益的期望。与奖励的区别是,价值倾向于衡量长远的收益,而奖励则反映的是眼下立即获得的收益。
- 轨迹(Trajectory):是由一系列的状态-动作-奖励构成的序列。
- 返回(Return):是指一个轨迹上每一步的奖励的总和,也成为总奖励。返回的基本作用是评价一个策略的好与坏。
参考文献:
- R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. 2018.
- L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement learning: A survey,” Journal of artificial intelligence research, vol. 4, pp. 237–285, 1996.
- https://en.wikipedia.org/wiki/Reinforcement_learning
致读者: 小时百科一直以来坚持所有内容免费无广告,这导致我们处于严重的亏损状态。 长此以往很可能会最终导致我们不得不选择大量广告以及内容付费等。 因此,我们请求广大读者热心打赏 ,使网站得以健康发展。 如果看到这条信息的每位读者能慷慨打赏 20 元,我们一周就能脱离亏损, 并在接下来的一年里向所有读者继续免费提供优质内容。 但遗憾的是只有不到 1% 的读者愿意捐款, 他们的付出帮助了 99% 的读者免费获取知识, 我们在此表示感谢。
友情链接: 超理论坛 | ©小时科技 保留一切权利