ChatGPT
贡献者: xzllxls
ChatGPT(Chat Generative Pre-trained Transformer)是一款由 OpenAI 组织推出的,通过多种语言大数据训练的基于 Transformer(转换器)的语言生成模型。该模型的主要功能是与人进行实时对话。
ChatGPT 模型可以对人类用户的提问进行回答,也可以接着用户的陈述,做进一步表述。在一次会话当中,该模型还可以记住之前的对话内容,并且对用户的追问和修正建议做适当反应。官方还宣称该模型会拒绝回答一些不适合的问题。与此同时,模型也存在一些局限性:很有可能产生错误的信息,有可能产生有害的建议或者有偏见的内容,以及对尚未训练过的知识了解有限。图 1 是官方提供的一个对话的例子。

图 1:对话例子
OpenA 目前尚未公开 ChatGPT 模型的原始论文和源程序。根据 ChatGPT 官方网站所提供的信息,训练该模型的方法是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)。此方法与早前的 InstructGPT 所使用的训练方法相同。ChatGPT 的训练流程主要是(见图 2):(1)收集大规模语言数据,训练监督策略;(2)收集比较数据,训练奖励模型;(3)用一种被称为"近端策略优化"的强化学习算法来进一步优化奖励模型。
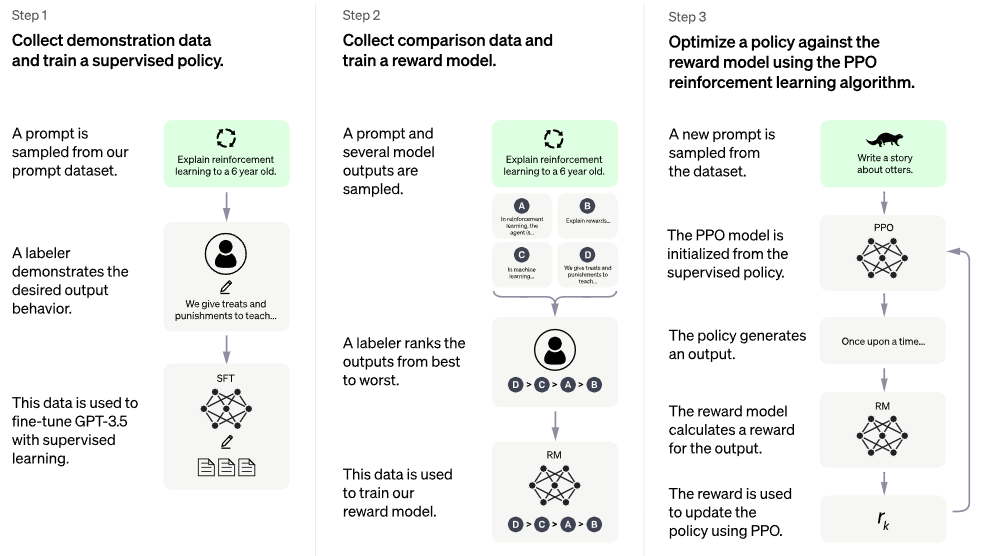
图 2:ChatGPT 模型的训练过程 [1]
当前的 ChatGPT 版本是在原来的 GPT-3.5 模型基础上通过精调(fine-tuning)得来的。训练设备采用的是 Azure 人工智能计算架构。
官网宣称模型具有以下局限性,并且分析了产生问题的原因和可能的改进方案:
- ChatGPT 有时会写出看似合理但不正确或荒谬的答案。解决这个问题具有挑战性,因为:(1)在强化学习训练期间,目前没有真实来源;(2) 训练模型更加谨慎导致它拒绝可以正确回答的问题;(3) 监督训练会误导模型,因为理想的答案取决于模型知道什么,而不是人类演示者知道什么。
- ChatGPT 对输入措辞的调整或多次尝试相同的提示很敏感。例如,给定一个问题的措辞,模型可以声称不知道答案,但只要稍作改写,就可以正确回答。
- 该模型通常过于冗长并过度使用某些短语,例如重申它是 OpenAI 训练的语言模型。这些问题源于训练数据的偏差(训练者更喜欢看起来更全面的更长答案)和众所周知的过度优化问题。 理想情况下,当用户提供模棱两可的查询时,模型会提出澄清问题。相反,我们当前的模型通常会猜测用户的意图。
- 虽然我们已努力使模型拒绝不当请求,但它有时会响应有害指令或表现出有偏见的行为。我们正在使用 Moderation API 来警告或阻止某类不安全的内容,但我们预计它目前会有一些漏报和漏报。我们渴望收集用户反馈,以帮助我们正在进行的改进该系统的工作。
参考文献:
- https://openai.com/blog/chatgpt/
致读者: 小时百科一直以来坚持所有内容免费无广告,这导致我们处于严重的亏损状态。 长此以往很可能会最终导致我们不得不选择大量广告以及内容付费等。 因此,我们请求广大读者热心打赏 ,使网站得以健康发展。 如果看到这条信息的每位读者能慷慨打赏 20 元,我们一周就能脱离亏损, 并在接下来的一年里向所有读者继续免费提供优质内容。 但遗憾的是只有不到 1% 的读者愿意捐款, 他们的付出帮助了 99% 的读者免费获取知识, 我们在此表示感谢。
友情链接: 超理论坛 | ©小时科技 保留一切权利