上海海事大学 2014 年数据结构
贡献者: xzllxls
1. 一.判断题(本题 10 分,每小题 1 分)
1、若某顺序表采用顺序存储结构,每个元素占 $10$ 个存储单元,首地址为 $200$,则下标为 $11$(第 $12$ 个)的元素的存储起始地址为 $320$。
2、若对线性表进行的主要操作不是插入和删除,则该线性表宜采用顺序存储结构。
3、对一个空栈按 $a,b,c,d,e,f,g$ 顺序依次读入,经过多次入栈和出栈的操作后,能得到按 $f,e,g,d,a,c,b$ 顺序的出栈序列。
4、假定在顺序表中每个位置插入的概率相同,向一个有 $64$ 个元素的顺序表中插入一个新元素并保持原来顺序不变,平均要移动 $33$ 个元素。
5、含有 $3$ 个结点(元素值均不相同)的二叉排序树共有 $30$ 种。
6、$n$ 个顶点的连通图至少有 $n-1$ 条边。
7、在无向图 $G$ 的邻接矩阵 $A$ 中,若 $A[i][j]$ 等于 $1$,则 $A[j][i]$ 等于 $0$。
8、采用顺序检索法在一个有 $123$ 个元素的有序顺序表中查找,若每个元素的查找概率相等,则成功检索的平均查找长度 $ASL$ 为 $61$。
9、在散列存储中,装载因子 $a$ 的值越大,发生冲突的可能性就越大。
10、快速排序是一种稳定的排序方法。
2. 二。填空题(本题 30 分,每空 2 分)
1.分析下列程序段,其时间复杂度分别为:((1))、((2)).
i=m=0;
while (m<n) {
i++; s+=i;
}
m=0;
for(i=1; i<=n; i++)
for(j=2*i; j<=n; j++)
m++;
2.广义表 $A=(a, (a, b), (i,j),k),d,e)$ 的长度是((3)),深度是((4)),取表头和表尾函数分别为 head()和 tail(),则 head(tail(head(tail(A))))=((5)),而从表中取出原子项 $j$ 的运算为((6))。
3.有一个二维数组 A.0.[2..9],每个数组元素占用 8 个存储单元,并且 A[2][5]的存储地址为 2080,若按行序为主序方式存储,数组元素 A[4][6]的存储地址是_ (7)
4.一棵完全二叉树有 $600$ 个结点,则它的深度是((8))。
5.已知一个图采用邻接矩阵表示,计算第 $i$ 个结点的入度的方法是((9))。
6.一个图的边集为{<A, B>,<A,C>,<A,E>,<B,C>, <B,D>, <C,D>, <E,B>,<E, D>},从顶点 A 出发进行深度优先搜索遍历访问顶点顺序为((10)), 从顶点 A 出发进行广度优先搜索遍历访问顶点顺序为((11)),对该图进行拓扑排序得到的顶点序列为((12)).
7.对 $12$ 个元素的序列进行直接插入排序时,最少的比较次数为((13))。
8.((14))排序方法采用的是二分法思想,在((15))情况下最不利于发挥其长处。
3. 三,选择题(本题 20 分,每空 2 分)
1.在数据结构中,从逻辑上可以把数据结构分成( )。
A.动态结构和静态结构 $\qquad$ B.紧凑结构和非紧凑结构
C.线性结构和非线性结构 $\qquad$ D.内部结构和外部结构
2.线性表若采用链式存储结构时,内存中可用存储单元的地址( )。
A.必须是连续的 $\qquad$ B.部分地址必须是连续的
C.一定是不连续的 $\qquad$ D.连续不连续都可以
3.线性表的顺序存储结构是一种( )的存储结构,而线性表的链式存储结构是一种随机存取的存储结构。
A.随机存取 $\qquad$ B.顺序存取
C.索引存取 $\qquad$ D.散列存取
4.在一个单链表中,已知 $q$ 所指结点是 $p$ 所指结点的前驱结点,若在 $q$ 和 $p$ 之间插入 $s$ 结点,则执行( )。
A. s->next=p->next; p->next=s; $\qquad$ B. p->next=s->next; s->next=p;
C. q->next=s;s->next=p; $\qquad$ D. p->next=s; s->next=q;
5.在双链表中的 $p$ 所指结点之后插入 $s$ 所指结点的操作是()。
A. p->next=s; s->prior-p; p->next->prior=s; s->next p->next;
B. p->next=s; p->next->prior=s; s->prior-p; s->next=p->next;
C. s->prior=p; s->next=p->next; p->next=s; p->next->prior=s;
D. s->prior-p; s->next=p->next; p->next->prior-s; p->next=s;
6.串是一种特殊的线性表,其特殊性体现在( )。
A.可以顺序存储 $\qquad$ B.数据元素是一个字符
C.可以链接存储 $\qquad$ D.数据元素可以是多个字符
7.以下( )是稀疏矩阵一般的压缩存储方法。
A.二维数组和三维数组 $\qquad$ B.三元组和散列
C.三元组和十字链表 $\qquad$ D.散列和十字链表
8.采用邻接表存储的图的深度优先遍历算法类似于二叉树的( )。
A.先序遍历 $\qquad$ B.中序遍历 $\qquad$ C.后序遍历 $\qquad$ D.按层遍历
9.以下不需进行关键字的比较的排序方法是( )。
A.快速排序 $\qquad$ B.归并排序 $\qquad$ C.基数排序 $\qquad$ D.起泡排序
10.有一个长度为 $12$ 的有序表,按二分查找法对该表进行查找,在表内各元素等概率情况下查找成功所需的平均比较次数为()。
A.35/12 $\qquad$ B.37/12 $\qquad$ C.39/12 $\qquad$ D.43/12
4. 四,应用题(本题 60 分,每小题 10 分)
1.已知一棵二叉树的先序序列和中序序列分别为,
先序序列: ABDEGHCFK
中序序列: DBGEHAFKC
请画出该树的结构并写出其后序序列。
2.右图是一个无向图,试分别用下列两种方法求它的最小生成树,并给出依次产生的边,连接顶点 i 和 j 边用<i, j>的形式表示。
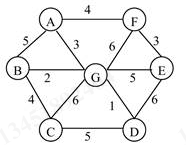
1)用普里姆算法从顶点 A 开始;
2)用克鲁斯卡尔算法。
3.某通信系统中共包含八个字符: A、B、C、D、E、F、G、H,它们出现频率分别为: 0.13. 0.19、0.07、0.14、0.16、0.22、0.03、0.06,试为它们构造一棵 Huffman 树(哈夫曼树),并设计这些字符的哈夫曼编码。
4.设散列表为 HT[0..14],即表的长度为 15。散列函数为: H(key)= key%13,采用线性探测再散列法解决冲突,若插入的关键码序列为{163, 151, 166, 143, 124, 138, 161, 158,130, 67, 232, 89, 213}。
1)试画出插入这 13 个关键码后的散列表。
2)计算在等概率情况下查找成功的平均查找长度 ASL。
5.对于正整数序列{59, 96,48,39, 86,75,38,18,66,92,22},建立一棵平衡二叉树,然后插入结点 32,分别画出该平衡二叉树及插入结点 32 后的平衡二叉树。
6.已知待排序记录的关键字序列为{ 501,120,539,983,185,852,276, 632,478,157, 528,616, 208},需要按关键字值递增的次序进行排序,请回答下列问题。
1)写出以第一个元素为基准的快速排序进行第一趟扫描后的结果;
2)堆排序初始建堆后结果。
5. 五.编程题(本题 30 分,每小题 10 分)
1.对给定的 $m$,编写一个函数求满足 $1*2+2*3+3+...+(n-1)*n<=m$ 的最大的 $n$。
2.试设计一个算法,通过遍历一趟单链表来调整结点顺序,将带头结点的单链表中所有 $data$ 域值小于零的结点都放在不小于零的结点之后。表头指针为 $first$,存储结构为:
typedef struct Node {
int data;
struct Node *next;
}Node,*List;
3.试编写函数输出二叉树中每一个结点的层数(设根结点的层数为 $1$)。二叉树用二叉链表存储,定义为:
typedef struct BiNode {
char data;
struct BiNode *lchild, *rchild;
}BiNode,* BiTree;
友情链接: 超理论坛 | ©小时科技 保留一切权利