过度拟合
贡献者: xzllxls
过度拟合(或称过拟合、过配,英文:overfitting)是指机器学习算模型在训练集上的误差和测试集上的误差之间差异过大。 造成过度拟合的原因可能有多种。最常见的就是模型容量过高,模型过于复杂,换句话说是模型假设所包含的参数数量过多。如此一来,算法会将训练集中所包含的没有普遍性的一些特征也学习进来,结果降低了模型的泛化能力。
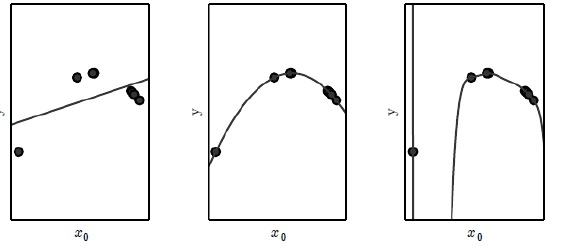
图 1 表示了欠拟合、恰当拟合和过度拟合三种情况。假设图中的几个训练数据的数据点所服从的数据分布更接近于抛物线。当我们在做机器学习数据拟合时,须要先选择一个参数化的模型形式。如果,我们选择的是一个简单线性模型,那么,就无法较好地拟合该训练数据,因为线性模型只能表示直线,无法较好地贴合呈抛物线形态分布的数据点(如图 1 左图),因此,模型欠拟合。此时,我们也可以称该模型学习容量不足。而如果,我们选择一个四次或者五次等高次函数作为学习器模型,训练时,可以完美拟合训练数据点。因为,高次函数完全可以表示抛物线(如图 1 右图)。但问题是当,新的仍然呈现抛物线型分布的数据点出现时,该模型可能就会产生较大误差。因为模型容量过大,它学习到了多余的信息。如果,我们选择的是二次函数作为回归模型,那么,不仅可以较好地拟合训练数据,当新的数据点出现时,模型也有较好的效果,此时,就成为恰当拟合。
机器学习从功能表现上与人类的学习类似。 打个可能不太恰当的比方,一个饱经沧桑,经历过各种复杂人际关系的人在遇到一个心思纯粹的人时,容易将对方想得很复杂,反而难以理解对方。这其实是因为他自己的经历所决定的。
过度拟合无法完全避免。在实际应用中,可以采用一些方法来尽可能减少过度拟合,例如,降低模型的复杂度,提前停止(Early stopping ),交叉验证(Cross-validation),或者正则化(Regularization)等方法。
提高模型泛化能力背后的哲学思想正是所谓的 “奥卡姆剃刀” 原理。此原理的意思是,在能够解释所观察到的现象的各种不同理论中,我们尽可能去选择那个最简单的理论。
参考文献:
- I. Goodfellow, Y. Bengio, A. Courville, and Y. Bengio, Deep learning, vol. 1, no. 2. MIT press Cambridge, 2016.
- 周志华. 机器学习[M]. 清华大学出版社,2016
- https://en.wikipedia.org/wiki/Overfitting