交叉验证
贡献者: xzllxls
交叉验证(Cross validation)是机器学习中的一种模型评估方法。该方法将数据划分成多个部分,然后轮流使用每个部分作为测试集,另一个部分作为训练集,多次训练和测试之后得出模型的平均性能。
如果把数据划分成 k 份,我们就称此时的验证方法为k-折交叉验证(k-fold cross validatioin)。详细过程是,将数据集分成 k 份,然后进行 k 次训练和测试,每次使用不同的 k-1 份数据作为训练集,剩余的一份数据作为测试集,最终得到 k 个性能指标的平均值。通过使用交叉验证,可以减少过拟合的风险,并提高模型的泛化能力。
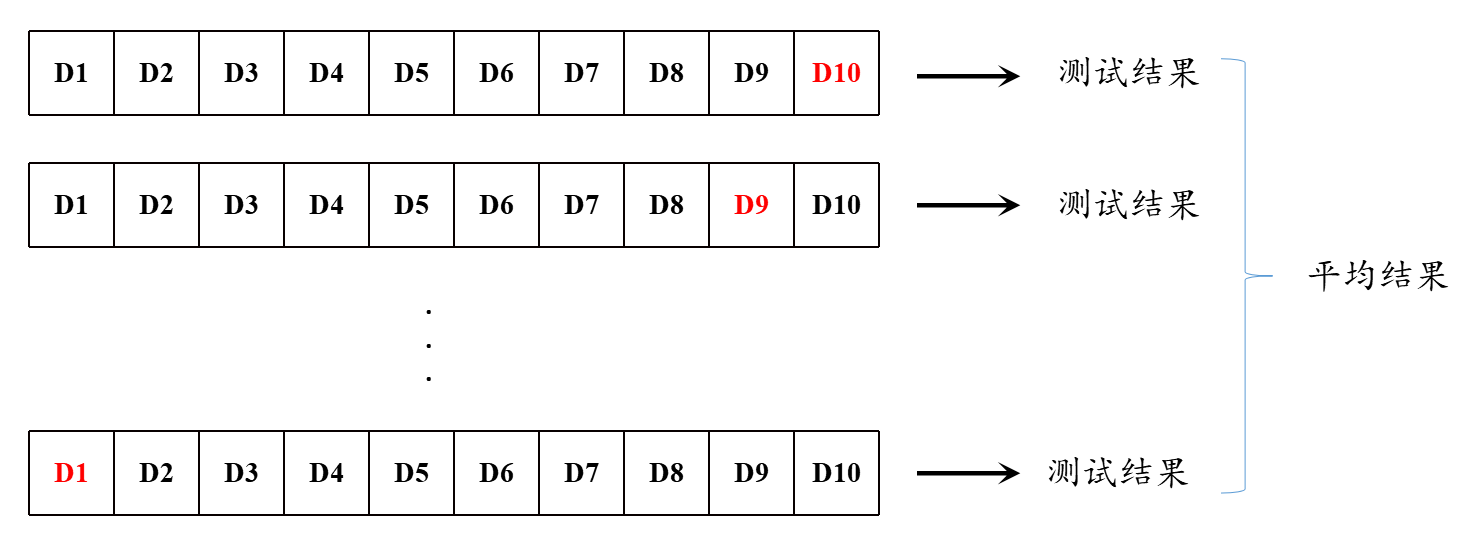
图 1 所表示的是十折交叉验证的过程。图中红色表示的是被用于测试的数据,其它部分均为训练数据。每次轮流选择一部分作为测试集,依次为:$D10$、$D9$,...$D1$,训练测试完之后得到一个模型性能的结果,最后取得一个平均值作为最后模型性能的评估结果。
交叉验证法的优势是使得训练数据中的每一个样本都被用于训练模型。弥补了留出法通常只能使用一部分数据用于训练的不足。
特别地,如果每次训练和测试时,只留一个样本作为测试,其余样本全部用于模型训练,那么,此时的交叉验证方式就称为留一法(leave-one-out, LOO)。留一法的优势是最大可能地使用了原始数据集来训练模型,使得训练出来的模型能够更好地拟合原数据。但是,这会带来一个问题,就是该模型的测试准确度可能有较大偏差,因为每次只有一个测试样本。
1. 知识要点
目的
交叉验证的目的是评估模型在未见过的数据上的性能表现。
方法
将数据集划分为多个子集,多个子集依次作为验证集,其余子集作为训练集,重复训练和评估过程,最终通过平均各次评估结果来估计模型性能。
k 折交叉验证(k-Fold Cross-Validation)
将数据集分为 k 个子集(折)。进行 k 次训练,每次使用 k-1 个子集训练模型,剩下的 1 个子集验证模型。最终的性能指标取 k 次评估结果的平均值。
留一法交叉验证(Leave-One-Out Cross-Validation, LOOCV)
特殊的 k 折交叉验证,其中 k 等于样本数量。每次用一个样本作为验证集,其余样本作为训练集。非常耗时,适用于小数据集。
交叉验证的优点
- 有效防止过拟合:通过多次训练和验证,模型评估更稳定。
- 更好利用数据:相比简单的训练-测试划分,交叉验证充分利用了数据集。
- 评估更可靠:提供了模型在不同数据划分下的性能估计,减少了训练集测试机划分的偶然性对模型性能评估的影响。
交叉验证的缺点
- 计算成本高:特别是对于大型数据集和复杂模型,计算时间较长。
- 实现复杂:相比简单的训练-测试划分,实现交叉验证稍显复杂。
2. 编程实战
给出一段实现了 5 折交叉验证的示例程序。程序训练了一个逻辑回归分类器,然后用 5 折交叉验证的方法评价了模型的分类准确率。算法基于 scikit-learn 机器学习库实现。
代码示例
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 定义模型
model = LogisticRegression(max_iter=200)
# 定义k折交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 评估模型性能
scores = cross_val_score(model, X, y, cv=kf, scoring='accuracy')
# 输出结果
print("交叉验证的准确率:", scores)
print("平均准确率:", scores.mean())
结果与说明
程序执行结果如下:
交叉验证的准确率: [1. 1. 0.93333333 0.96666667 0.96666667]
平均准确率: 0.9733333333333334