图灵测试(综述)
贡献者: 待更新
本文根据 CC-BY-SA 协议转载翻译自维基百科相关文章。
图灵测试,最初由艾伦·图灵于 1949 年提出,称为 “模仿游戏”,是对机器是否能够表现出等同于人类的智能行为的测试,或者说是无法与人类行为区分的测试。图灵提出,测试中一位人类评估者将判断人类与机器之间的自然语言对话,机器被设计成产生类似人类的回应。评估者知道对话中的一方是机器,所有参与者都将被隔开。对话仅限于文字交流,例如使用计算机键盘和屏幕,因此测试结果不依赖于机器将文字转化为语音的能力。如果评估者无法可靠地区分机器与人类,那么机器就被认为通过了测试。测试的结果不依赖于机器是否能给出正确答案,而是看它的答案与人类回答的相似程度。由于图灵测试是对性能能力无法区分性的测试,因此其语言版本自然地推广到了所有人类的表现能力,包括语言和非语言(机器人)的表现能力。
该测试由图灵在 1950 年发表的论文《计算机与智能》中提出,当时他在曼彻斯特大学工作。论文开头写道:“我提议考虑这个问题,‘机器能思考吗?’” 由于 “思考” 这一概念很难定义,图灵选择用 “用另一种更相关且表达相对明确的话语替代这个问题” 来描述问题。[6] 图灵以 “三人游戏” 的形式来描述这一问题,这个游戏称为 “模仿游戏”,在这个游戏中,一位询问者通过向一位男士和一位女士提问,试图判断两位参与者的性别。图灵的新问题是:“是否存在可以在模仿游戏中表现得很好的数字计算机?”[2] 图灵认为这个问题是可以回答的。在论文的其余部分,他反驳了关于 “机器能思考” 这一命题的所有主要反对意见。[7]
自从图灵提出他的测试以来,它既具有深远的影响,也受到了广泛的批评,并成为人工智能哲学中的一个重要概念。[8][9] 哲学家约翰·塞尔在他的 “中文房间” 论证中评论了图灵测试,这一思想实验认为,无论程序如何使计算机表现得像人类,机器都无法拥有 “思维”、“理解” 或 “意识”。塞尔批评图灵的测试,并声称它不足以检测意识的存在。
1. 聊天机器人
图灵测试后来促成了 “聊天机器人” 的发展,这些人工智能软件实体的唯一目的是与人进行文本聊天。今天,聊天机器人有了更广泛的定义;它是一个能够与人进行对话的计算机程序,通常通过互联网进行。OED[10][11]
ELIZA 和 PARRY
1966 年,Joseph Weizenbaum 创建了一个名为 ELIZA 的程序。该程序通过检查用户输入的评论中的关键词来工作。如果找到了关键词,就会应用一个规则来转换用户的评论,并返回生成的句子。如果没有找到关键词,ELIZA 则会以一个通用的回答或通过重复之前的评论来回应。[12] 此外,Weizenbaum 将 ELIZA 开发为模拟罗杰斯式心理治疗师的行为,使得 ELIZA 能够 “自由地假设几乎对真实世界一无所知”。[13] 通过这些技术,Weizenbaum 的程序能够让一些人相信他们在与一个真人对话,甚至有些人 “非常难以相信 ELIZA [...] 不是人类”。[13] 因此,有些人认为 ELIZA 是第一个能够通过图灵测试的程序,[13][14] 尽管这一观点存在很大争议(参见下文 “询问者的天真”)。
1972 年,Kenneth Colby 创建了 PARRY,一个被描述为 “带有态度的 ELIZA” 的程序。[15] 它试图模拟偏执型精神分裂症患者的行为,采用与 Weizenbaum 类似(但更先进)的方法。为了验证该工作,PARRY 在 1970 年代早期通过图灵测试的变体进行了测试。一个由经验丰富的精神科医生组成的小组分析了通过电传打字机传输的真实病人与运行 PARRY 的计算机的对话。另一个由 33 名精神科医生组成的小组则查看了对话记录。随后,这两个小组被要求识别哪些 “病人” 是人类,哪些是计算机程序。[16] 精神科医生们仅有 52%的正确识别率——这一数据与随机猜测相符。[16]
尤金·古斯特曼 (Eugene Goostman)
2001 年,在俄罗斯圣彼得堡,由三位程序员——俄罗斯出生的弗拉基米尔·维谢洛夫、乌克兰出生的尤金·德门琴科和俄罗斯出生的谢尔盖·乌拉森——开发了一个名为 “尤金·古斯特曼” 的聊天机器人。2014 年 7 月 7 日,它成为了第一个看似通过图灵测试的聊天机器人,在英国雷丁大学举办的纪念阿兰·图灵 60 周年忌日的活动中,三分之一的评委认为古斯特曼是人类;活动组织者凯文·沃里克认为它通过了图灵测试。古斯特曼被描绘为一位来自乌克兰敖德萨的 13 岁男孩,拥有一只豚鼠宠物和一位妇科医生父亲。选择这个年龄是故意的,目的是让与他 “对话” 的人原谅他回答中的小语法错误。[10][17][18]
Google LaMDA
2022 年 6 月,谷歌的 LaMDA(对话应用的语言模型)聊天机器人因被声称具备意识而广泛报道。最初在《经济学人》的一篇文章中,谷歌研究员布莱斯·阿圭拉·亚卡斯表示,LaMDA 展示了对社会关系的某种理解。[19] 几天后,谷歌工程师布莱克·莱莫因在《华盛顿邮报》的采访中声称,LaMDA 已具备意识。莱莫因因内部提出这一观点而被谷歌停职。阿圭拉·亚卡斯(谷歌副总裁)和詹·吉奈(负责创新的负责人)调查了这一说法,但驳回了它们。[20] 莱莫因的主张遭到该领域其他专家的普遍反对,指出一个看似模仿人类对话的语言模型,并不意味着其背后存在任何智能,[21] 尽管它似乎通过了图灵测试。关于 LaMDA 是否已经达到意识的讨论在支持和反对双方的推动下,激起了社交媒体平台上的广泛讨论,包括对 “意识” 意义的定义,以及什么才是 “人类” 的问题。
ChatGPT
OpenAI 发布的聊天机器人 ChatGPT,基于 GPT-3.5 和 GPT-4 大语言模型,于 2022 年 11 月推出。Celeste Biever 在《自然》杂志的文章中写道,“ChatGPT 突破了图灵测试”。[22] 斯坦福大学的研究人员报告称,ChatGPT 通过了图灵测试;他们发现 ChatGPT-4 “通过了严格的图灵测试,偏离普通人类行为,主要是表现得更加合作”。[23][24]
虚拟助手
虚拟助手也是基于人工智能的软件代理,旨在通过文本或语音命令回应指令或问题并执行任务,因此它们自然也包含了聊天机器人的功能。面向消费者的知名虚拟助手包括苹果的 Siri、亚马逊的 Alexa、谷歌助手、三星的 Bixby 和微软的 Copilot。[25][26][27][28]
恶意软件
这些程序的版本仍然能够欺骗用户。“CyberLover” 是一个恶意软件程序,通过说服用户 “透露个人身份信息或引导他们访问将恶意内容传送到计算机的网站” 来攻击互联网用户。[29] 该程序已成为一种 “情人节风险”,通过与 “寻求在线关系” 的人进行调情,收集他们的个人数据。[30]
2. 历史
哲学背景
机器是否能够思考的问题有着悠久的历史,深深植根于心灵的二元论和物质主义观点的区别中。勒内·笛卡尔在 1637 年的《方法谈》中预示了图灵测试的某些方面,他写道:
[H]ow many different automata or moving machines could be made by the industry of man ... For we can easily understand a machine's being constituted so that it can utter words, and even emit some responses to action on it of a corporeal kind, which brings about a change in its organs; for instance, if touched in a particular part it may ask what we wish to say to it; if in another part it may exclaim that it is being hurt, and so on. But it never happens that it arranges its speech in various ways, in order to reply appropriately to everything that may be said in its presence, as even the lowest type of man can do.[31]
笛卡尔在这里指出,自动机能够对人类的互动作出反应,但他认为这些自动机无法像任何人类那样恰当地回应其面前所说的任何话。因此,笛卡尔通过将适当的语言反应的不足定义为区分人类和自动机的标准,预示了图灵测试。笛卡尔并未考虑到未来的自动机可能克服这种不足,因此他并未提出图灵测试,即使他预示了其概念框架和标准。
丹尼斯·狄德罗在 1746 年的《哲学思考》一书中提出了一个图灵测试标准,尽管其隐含的限制假设是参与者必须是自然的有生命的存在,而非考虑人工创造的物体:
如果他们发现一只能够回答所有问题的鹦鹉,我会毫不犹豫地认为它是一个智能生物。
这并不意味着他同意这个观点,而是表明这已经是当时物质主义者普遍的论点。
根据二元论,心灵是非物质的(或至少具有非物质的特性),因此无法用纯粹的物理术语解释。而根据物质主义,心灵可以用物理的方式来解释,这为人工产生的心灵打开了可能性。
1936 年,哲学家阿尔弗雷德·艾耶考虑了标准的哲学问题——其他心灵的问题:我们如何知道其他人是否拥有与我们相同的意识体验?在他的书《语言、真理与逻辑》中,艾耶提出了一种区分有意识的人和无意识机器的协议:“我只能通过一个经验测试来断言一个看似有意识的物体实际上并非一个有意识的存在,而只是一个傀儡或机器,这个测试通过判断是否具备意识来确定。”[34](这一建议与图灵测试非常相似,但不确定艾耶的哲学经典是否为图灵所熟知。)换句话说,如果一个物体未能通过意识测试,则它不是有意识的。
文化背景
图灵测试的一个初步概念出现在乔纳森·斯威夫特 1726 年出版的小说《格列佛游记》中。[35][36] 当格列佛被带到布罗卑丁纳国的国王面前时,国王最初认为格列佛可能是 “某种钟表机械(在那个国家已经达到了极高的完美程度),由某位聪明的艺术家设计”。即使他听到格列佛说话,国王仍然怀疑格列佛是否被教会了 “某些词语”,以便让他 “以更高的价格出售”。格列佛告诉国王,直到 “他向我提出了几个其他问题,并且仍然得到了理性的回答”,国王才确信格列佛不是一台机器。[37]
到 1940 年代,科幻小说中已经形成了通过人类判断计算机或外星人是否智能的传统,图灵很可能会意识到这些作品。[38] 斯坦利·G·温鲍姆的《火星奥德赛》(1934 年)就提供了一个例子,展示了这些测试如何变得复杂。[38]
早期的机器或自动装置试图伪装成人类的例子包括古希腊神话中的皮格马利翁,他创造了一个女性雕像,由爱神阿佛洛狄忒赋予生命;卡洛·科洛迪的小说《木偶奇遇记》,讲述了一个渴望变成真实男孩的木偶;以及 E·T·A·霍夫曼的 1816 年故事《沙人》,其中主人公爱上了一个自动人。在这些例子中,人们被那些能够在一定程度上伪装成人类的人工存在所愚弄。[39]
艾伦·图灵与模仿游戏
在人工智能(AI)研究领域成立之前,英国的研究人员已经探讨了 “机器智能” 长达十年之久。[40] 这也是英国赛博网络学和电子学研究者组成的非正式团体——比例俱乐部成员讨论的一个常见话题,其中包括艾伦·图灵。[41]
特别是图灵,自至少 1941 年起就开始了关于机器智能的研究,[42] 他在 1947 年首次提到 “计算机智能” 的概念。[43] 在图灵的报告《智能机械》中,[44] 他探讨了 “机械是否能够表现出智能行为” 的问题,[45] 并在这一研究过程中,提出了可能被视为他后续测试的前身:
“设计一个纸质机器,能够下出一盘不算太差的国际象棋并不难。[46] 现在,设定三个人 A、B 和 C 作为实验对象。A 和 C 是较差的国际象棋选手,B 是操作纸质机器的操控者……使用两个房间,并有某种通讯方式传递走棋,C 与 A 或纸质机器之间进行一局棋局。C 可能会觉得很难分辨自己到底是在和谁对弈。”[47]
《计算机械与智能》(1950 年)是图灵首次专门关注机器智能的已发表论文。图灵在这篇 1950 年的论文中开头提出,“我打算考虑‘机器能否思考’这个问题。”[6] 他指出,传统的处理此类问题的方法是从定义开始,定义 “机器” 和 “思考” 这两个术语。图灵选择不这么做;相反,他将问题转化为一个与之紧密相关且表述较为明确的新问题。[6] 本质上,他将问题从 “机器能否思考” 转变为 “机器能否做我们(作为思考的实体)能够做的事情?”[48] 图灵认为,新的问题的优点在于,它能够 “清楚地划分人类的身体能力和智力能力”[49]。
为了展示这种方法,图灵提出了一个灵感来源于派对游戏的测试,称为 “模仿游戏”,在这个游戏中,一男一女分别进入不同的房间,客人们通过写一系列问题并阅读打字机发回的答案,试图辨别他们的身份。在这个游戏中,男方和女方都试图说服客人相信自己是对方。(Huma Shah 认为,图灵之所以提出这个两人版的游戏,实际上是为了引导读者理解机器与人类的问答测试。[50])图灵描述了他的新版本游戏如下:
“现在我们问这个问题,‘当一台机器在游戏中扮演 A 的角色时,会发生什么?’在这种情境下,询问者是否会像在男与女之间的游戏中那样,错误地判断两者的身份?这些问题替代了我们原来的问题‘机器能否思考’。”[49]
在论文的后面,图灵提出了一种 “等效” 的替代形式,涉及一个法官与计算机和人类对话。[51] 尽管这些形式中的任何一种都不完全符合今天更为普遍认知的图灵测试版本,但他在 1952 年提出了第三种版本。在这个版本中,图灵在 BBC 广播中讨论过,陪审团向计算机提问,计算机的角色是让大部分陪审团成员相信它真的就是一个人。[52]
图灵的论文考虑了九个假设的反对意见,这些反对意见包括一些在论文发表后多年提出的反对人工智能的主要论点(见《计算机械与智能》)。[7]
中文房间
约翰·塞尔(John Searle)在 1980 年的论文《心灵、大脑与程序》中提出了 “中文房间” 思想实验,并认为图灵测试不能用来判断一台机器是否能够思考。塞尔指出,像 ELIZA 这样的程序仅通过操纵符号(它们并不理解这些符号)就能通过图灵测试。没有理解,它们不能像人类那样被描述为 “思考”。因此,塞尔得出结论,图灵测试不能证明机器能够思考。[53] 像图灵测试本身一样,塞尔的论点既受到广泛的批评[54],也得到了支持。[55]
塞尔等人在心灵哲学领域的论争激发了关于智能的本质、具有意识的机器是否可能以及图灵测试的价值的更激烈辩论,这一辩论持续到了 1980 年代和 1990 年代。[56]
洛布纳奖
洛布纳奖提供了一个每年举行的实际图灵测试平台,第一次比赛于 1991 年 11 月举行。[57] 该奖项由休·洛布纳(Hugh Loebner)资助。位于美国马萨诸塞州剑桥市的行为学研究中心曾组织了 2003 年之前的所有比赛。正如洛布纳所描述的,创建这个比赛的一个原因是推动人工智能研究的进展,至少部分原因是,尽管讨论图灵测试已经有 40 年,但没有人采取实际步骤去实施它。[58]
1991 年的首次洛布纳奖比赛引发了关于图灵测试可行性及其追求价值的重新讨论,这在大众媒体[59]和学术界[60]中都有所体现。第一次比赛的获胜者是一个没有明确智能的程序,它成功地欺骗了天真的询问者,做出了错误的判断。这突出了图灵测试的几个缺陷(见下文讨论):获胜者至少部分因为能够 “模仿人类的打字错误” 而获胜;[59] 这些不成熟的询问者容易被欺骗;[60] 一些人工智能研究人员认为,图灵测试只是从更有成果的研究中分散注意力。[61]
银奖(仅文本)和金奖(包括音频和视频奖)从未有人获得。然而,每年都会颁发铜奖,奖励那些在评委看来,表现出 “最人类化” 对话行为的计算机系统。人工语言互联网计算机实体(A.L.I.C.E.)在最近几年(2000、2001、2004 年)三度获得铜奖。学习型人工智能 Jabberwacky 在 2005 年和 2006 年获得了奖项。
洛布纳奖考察的是对话智能,获奖者通常是聊天机器人程序或人工对话实体(ACE)。早期的洛布纳奖规则限制了对话的主题:每个参赛者和隐藏的人类只能讨论单一话题,[62] 这样,询问者每次与实体互动时只能提出一个问题方向。1995 年,洛布纳奖取消了对话限制规则。在 2003 年的洛布纳奖上,位于萨里大学的比赛中,每个询问者有五分钟的时间与实体(无论是机器还是隐藏人类)互动。从 2004 年到 2007 年,洛布纳奖的互动时间超过二十分钟。
CAPTCHA
CAPTCHA(完全自动化公共图灵测试区分计算机与人类)是人工智能领域最早的概念之一。CAPTCHA 系统通常用于在线区分人类和机器人。它基于图灵测试。通过显示扭曲的字母和数字,它要求用户识别并输入这些字母和数字,机器人通常难以完成这个任务。[10][63]
reCaptcha 是 Google 拥有的一种 CAPTCHA 系统。reCaptcha v1 和 v2 版本要求用户匹配扭曲的图片或识别扭曲的字母和数字。reCaptcha v3 则设计为不打扰用户,在页面加载或点击按钮时自动运行。这种 “隐形” CAPTCHA 验证在后台进行,不会出现挑战,因此能够过滤掉大多数基本的机器人。[64][65]
3. 版本
Saul Traiger 认为,图灵测试至少有三个主要版本,其中两个在《计算机机械与智能》一文中有所描述,另一个则被他称为 “标准解释”。[66] 虽然关于 “标准解释” 是否是图灵所描述的,或者是对他论文的误读存在一些争议,但这三个版本并不被视为等同的,它们的优缺点各不相同。[66][67]
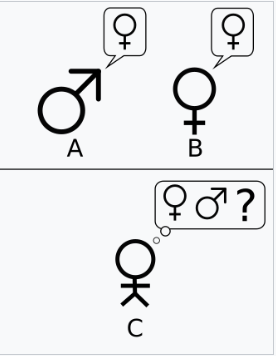
图灵的原始文章描述了一个简单的聚会游戏,涉及三名玩家。玩家 A 是男性,玩家 B 是女性,玩家 C(充当审问者角色)可以是任意性别。在模仿游戏中,玩家 C 看不见玩家 A 和玩家 B,只能通过书面笔记与他们沟通。玩家 C 通过向玩家 A 和玩家 B 提问,试图确定哪位是男性,哪位是女性。玩家 A 的角色是欺骗审问者,让其做出错误的判断,而玩家 B 则试图帮助审问者做出正确的判断。[8]
接下来,图灵提出:
“当一台机器在这个游戏中扮演 A 的角色时,会发生什么?当游戏以这种方式进行时,审问者是否像在人与女人之间的游戏中那样经常做出错误判断?” 这些问题取代了我们原来的问题:“机器能思考吗?”[49]
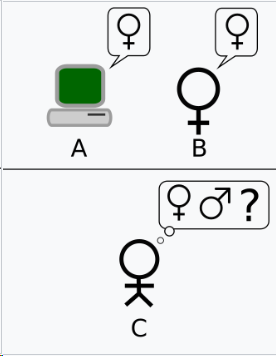
第二个版本出现在 Turing 的 1950 年论文中。与原始的模仿游戏测试类似,玩家 A 的角色由计算机扮演。然而,玩家 B 的角色由一名男性而不是女性扮演。
让我们专注于某个特定的数字计算机 C。是否可以通过修改这台计算机,使其具备足够的存储、适当提高其处理速度,并为其提供合适的程序,从而使 C 能够在模仿游戏中令人满意地扮演 A 的角色,而 B 的角色由一名男性扮演?[49]
在这个版本中,玩家 A(计算机)和玩家 B 都试图欺骗审问者做出错误的决定。
标准解释并未出现在原始论文中,但它既被接受也被争议。普遍的理解是,图灵测试的目的并不是专门为了确定计算机是否能够让审问者相信它是人类,而是看计算机是否能够模仿人类。[8] 虽然有争议是否图灵的原意就是这种解释,Sterrett 认为是的[68],因此将第二个版本与此版本混为一谈,而其他人(如 Traiger)则不这样看[66]——然而,这仍然导致了所谓的 “标准解释”。在这个版本中,玩家 A 是计算机,玩家 B 是任何性别的人。审问者的角色不再是确定哪一方是男性,哪一方是女性,而是要辨别哪一方是计算机,哪一方是人类。[69] 标准解释的根本问题在于,审问者无法区分哪一方是人类,哪一方是机器。虽然关于时长问题存在争议,但标准解释通常认为这是一个合理的限制。
4. 解释
关于图灵测试的不同表述,出现了争议,究竟图灵想要提出哪一种版本的测试。[68] Sterrett 认为,可以从图灵 1950 年的论文中提取出两个不同的测试,并且反对图灵的说法,认为它们并不等同。采用派对游戏并比较成功频率的测试被称为 “原始模仿游戏测试”(Original Imitation Game Test),而由一个人类审问者与一台计算机和一个人类对话组成的测试,则被称为 “标准图灵测试”(Standard Turing Test),同时 Sterrett 将这个测试与 “标准解释” 视为等同,而不是与模仿游戏的第二个版本等同。[66] Sterrett 认为标准图灵测试(STT)存在批评者指出的各种问题,但他认为,原始模仿游戏测试(OIG 测试)在定义上能避免很多问题,原因在于一个关键的区别:与 STT 不同,OIG 测试并不将与人类表现的相似性作为标准,尽管它在设定机器智能的标准时采用了人类表现。一个人可以未能通过 OIG 测试,但有人认为这是智能测试的优点,因为失败表明缺乏应变能力:OIG 测试要求的是与智能相关的应变能力,而不仅仅是 “模拟人类对话行为”。OIG 测试的一般结构甚至可以用于非语言版的模仿游戏。[70]
Huma Shah 认为,图灵本人关心的是机器是否能够思考,并提供了一种简单的检验方法:通过人与机器的问答环节。[71] Shah 认为,图灵描述的模仿游戏可以通过两种方式实施:a)一对一的审问者与机器测试,b)让审问者同时对比机器和人类,二者并行接受提问。[50]
其他一些学者[72]则解释图灵提出的模仿游戏本身就是测试,而没有明确说明如何考虑图灵声明的那一点,即他提出的使用派对版本模仿游戏的测试,是基于该模仿游戏中成功频率的比较标准,而不是一次游戏回合的成功能力。
一些学者认为,理解图灵的模仿游戏应该侧重于其社会性方面。在其 1948 年的论文中,图灵将智能视为一种 “情感概念”,并指出:
“我们认为某物表现得智能的程度,很大程度上取决于我们的心态和训练,而不仅仅是所考虑对象的性质。如果我们能够解释和预测它的行为,或者它似乎没有什么潜在的计划,我们就不容易认为它是智能的。因此,同样的对象,一个人可能认为它是智能的,而另一个人则不会;第二个人会发现它行为的规则。”[73]
基于这一观点以及图灵其他类似的论述,Diane Proudfoot[74]认为图灵持有响应依赖理论(response-dependence approach)来理解智能,即智能(或思考的)实体是一个在普通审问者眼中看起来很智能的实体。Bernardo Gonçalves 指出,尽管图灵在介绍他的测试时使用了将其视为决定机器是否能思考的关键实验的修辞[75],但他实际呈现的测试符合现代科学传统中伽利略式的思想实验的特征。[76] Shlomo Danziger[77]则提出一种社会技术解释,认为图灵把模仿游戏看作不仅仅是一个智能测试,而是一个技术上的愿景——实现这一愿景可能涉及社会对机器态度的变化。根据这种解释,图灵所著名的 50 年预测——即到 20 世纪末,某台机器将通过他的测试——实际上包含了两个可以区分的预测。第一个是技术预测:
“我相信大约五十年后,人们将能够编程计算机……使它们在模仿游戏中表现得足够好,以至于普通审问者在五分钟提问后,正确识别的概率不会超过 70
第二个预测是社会学预测:
“我相信到世纪末,言语的使用和普遍的教育性观点将发生如此大的变化,以至于人们能够谈论机器是否会思考,而不会期待受到反驳。”[78]
Danziger 进一步声称,对于图灵来说,改变社会对机器的态度是智能机器存在的前提:只有当 “智能机器” 不再被视为自相矛盾的说法时,智能机器的存在才成为逻辑上可能。
Saygin 曾建议,或许原始游戏是一种提出较少偏见的实验设计方式,因为它隐藏了计算机的参与。[79] 模仿游戏还包括标准解释中没有的 “社会黑客”,因为在游戏中,计算机和男性人类都需要假装成他们不是的人。[80]
审问者是否应当知道计算机的存在?
任何实验室测试的关键是应当有一个对照组。图灵从未明确说明在他的测试中,审问者是否知道其中一个参与者是计算机。他只提到,玩家 A 将被机器替代,并未提到玩家 C 是否应当知道这一替代。[49] 当 Colby、FD Hilf、S Weber 和 AD Kramer 测试 PARRY 时,他们假设审问者在审问过程中无需知道被访者中是否有计算机的参与。[81] 正如 Ayse Saygin、Peter Swirski[82]等人所指出的,这对测试的实施和结果有很大的影响。[8] 在一项实验研究中,Ayse Saygin 使用了 1994 到 1999 年间 Loebner 奖一对一(审问者-隐藏对话者)人工智能竞赛的记录,探讨了 Grice 准则的违反,发现知道计算机参与与不知道计算机参与的参与者的反应之间存在显著差异。[83]
5. 优点
可操作性与简洁性
图灵测试的力量和吸引力来源于其简洁性。心灵哲学、心理学和现代神经科学无法提供足够精确和普遍的 “智能” 和 “思维” 定义,以便应用于机器。没有这些定义,人工智能哲学中的核心问题就无法得到解答。图灵测试,即使不完美,至少提供了一些可以实际衡量的内容。因此,它是回答这一困难哲学问题的务实尝试。
主题广度
测试的格式允许审问者向机器提供广泛的智力任务。图灵曾写道:“问答法似乎适合引入几乎任何我们希望包含的人类努力领域。”[84] 约翰·霍金兰(John Haugeland)补充道:“理解单词是不够的;你还必须理解主题。”[85]
为了通过一个设计良好的图灵测试,机器必须能够使用自然语言、推理、具备知识并进行学习。测试可以扩展为包括视频输入,以及一个可以传递物品的 “舱口”:这将迫使机器展示出熟练使用精心设计的视觉和机器人技术的能力。所有这些加在一起,几乎涵盖了人工智能研究希望解决的所有主要问题。[86]
费根鲍姆测试(Feigenbaum Test)旨在利用图灵测试可应用的广泛主题范围。它是图灵问答游戏的一个有限形式,将机器与文学或化学等特定领域的专家能力进行比较。
强调情感与美学智能
作为剑桥大学数学荣誉毕业生,图灵本应被期望提出一种要求计算机具备某一高度专业领域知识的智能测试,从而预示着一种更现代的研究方法。然而,正如前面提到的,图灵在其 1950 年奠基性的论文中描述的测试要求计算机能够成功地在一种常见的聚会游戏中竞争,通过回答一系列问题表现得像一个典型的男人,欺骗审问者,使其相信计算机是女性选手。
鉴于人类性别二态性是最古老的主题之一,因此上述情境隐含了一个事实,即要回答的问题既不涉及专业的事实知识,也不涉及信息处理技术。对计算机而言,挑战在于展示对女性角色的共情,并且展现出一种典型的美学敏感性——这两种特质在图灵想象的这一段对话中得到了体现:
审问者:X,请告诉我他的或她的头发长度? 选手:我的头发是层叠的,最长的发丝大约是九英寸长。 当图灵在他想象的对话中引入一些专业知识时,话题并不是数学或电子学,而是诗歌:
审问者:在你诗篇的第一行 “Shall I compare thee to a summer's day” 中,“春天的一天” 会不会同样适合,或者更好? 选手:那不符合韵律。 审问者:“冬天的一天” 呢?那样符合韵律。 选手:是的,但没有人愿意被比作冬天的一天。
图灵再次展示了他对共情和美学敏感性的兴趣,作为人工智能的组成部分;考虑到越来越多的对 “失控的 AI” 威胁的关注,[87] 有人提出[88],这种关注可能代表了图灵的一个重要直觉——即情感和美学智能将在创建 “友好 AI” 中发挥关键作用。然而,进一步指出的是,图灵能够在这一方向提供的灵感取决于他原始愿景的保存,也就是说,进一步说明,“标准解释” 图灵测试的推广——即仅关注话语智能的解释——必须谨慎对待。
6. 缺点
图灵并没有明确指出图灵测试可以作为衡量 “智能” 或其他任何人类特质的标准。他想提供一个清晰易懂的替代词,以替代 “思考” 这一词汇,这样他就可以用它来回应关于 “思维机器” 可能性的批评,并提出研究如何向前推进的建议。
然而,图灵测试被提出作为衡量机器 “思考能力” 或 “智能” 的标准。这个提议受到了哲学家和计算机科学家的批评。该解释假设审问者可以通过将机器的行为与人类的行为进行比较,从而判断机器是否 “思考”。这个假设的每个要素都受到了质疑:审问者判断的可靠性、将机器与人类进行比较的价值、以及仅仅比较行为的价值。由于这些以及其他的考虑因素,一些人工智能研究者对该测试与他们领域的相关性提出了质疑。
审问者的天真
在实际应用中,测试的结果往往容易被审问者的态度、技能或天真所主导,而非计算机的智能。许多领域的专家,包括认知科学家加里·马库斯(Gary Marcus),坚持认为图灵测试只是展示了人类多么容易被愚弄,而不是机器智能的标志。[89]
图灵在他对测试的描述中并未具体说明审问者需要具备哪些技能和知识,但他确实使用了 “平均审问者” 这一术语:“[平均审问者]在五分钟的提问后,正确判断的几率不会超过 70
像 ELIZA 这样的聊天机器人程序曾多次让毫无戒心的人相信他们正在与人类交流。在这些情况下,“审问者” 甚至没有意识到他们可能正在与计算机互动。为了成功地表现得像人类,机器不需要具备任何智能,只需与人类行为有表面上的相似性即可。
早期的洛布纳奖(Loebner Prize)比赛使用了 “简单” 的审问者,这些审问者很容易被机器欺骗。[60] 从 2004 年开始,洛布纳奖的组织者开始在审问者中安排哲学家、计算机科学家和记者。然而,其中一些专家也被机器所欺骗。[90]
图灵测试的一个有趣特征是 “共谋效应” 的频率,即当 “共谋者”(被测试的人类)被审问者误认为是机器时。有人提出,审问者认为人类反应的方式不一定是典型的人类反应。因此,一些人可能会被归类为机器。这样就可能有利于与之竞争的机器。人类被指示要 “表现自己”,但有时他们的回答更像是审问者期望机器说的话。[91] 这就引出了一个问题,即如何确保人类有动力 “表现得像人类”。
人类智能与一般智能
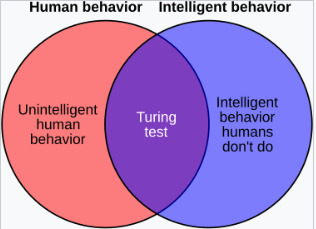
图灵测试并不直接测试计算机是否表现得聪明,而是仅仅测试计算机是否表现得像人类。由于人类行为和智能行为并不完全相同,因此该测试可能通过两种方式未能准确衡量智能:
1. 一些人类行为并不智能
图灵测试要求机器能够执行所有人类行为,无论这些行为是否智能。它甚至测试那些可能根本不被认为是智能的行为,如容易受侮辱、撒谎的诱惑或仅仅是频繁的打字错误。如果一台机器不能详细模仿这些不智能的行为,它就会失败。
这一反对意见由《经济学人》在 1992 年首届洛布纳奖比赛后不久发表的一篇名为《人工愚蠢》的文章提出。文章指出,首位洛布纳奖获胜者的成功,至少部分归功于其能够 “模仿人类的打字错误”。[59] 图灵本人曾建议,程序应在输出中加入错误,以便更好地 “玩” 这个游戏。[93]
2. 一些智能行为是不人类的
图灵测试并不测试那些高度智能的行为,如解决难题或提出原创见解的能力。实际上,它特别要求机器进行欺骗:如果机器比人类更智能,它必须故意避免表现得过于聪明。如果它解决了一个对人类来说几乎不可能解决的计算问题,那么审问者就会知道该程序不是人类,机器就会失败。
由于它无法衡量超越人类能力的智能,该测试不能用来构建或评估比人类更智能的系统。因此,已经提出了几种能够评估超智能系统的测试替代方案。[94]
意识与意识的模拟
图灵测试严格关注的是被测试者的行为——即机器的外部行为。在这一方面,图灵测试采取了行为主义或功能主义的方法来研究心智。ELIZA 的例子表明,一台通过图灵测试的机器可能通过遵循一长串机械规则来模拟人类的对话行为,而不需要具备思维或意识。
约翰·塞尔(John Searle)主张,外部行为不能用来判断一台机器是否 “真正” 在思考,或仅仅是在 “模拟思考”。他的中文房间论证旨在表明,即使图灵测试是智能的一个良好操作定义,它也可能无法表明机器拥有心智、意识或意向性(意向性是指思维具有 “关于” 某事的能力)。
图灵在他的原始论文中预见到了这一批评,并写道:
“我并不希望给人留下这样的印象,即我认为意识没有谜团。例如,任何试图将其局部化的尝试都涉及某种悖论。但我认为这些谜团不一定需要在我们回答本文所关心的问题之前解决。”
不切实际与不相关性:图灵测试与人工智能研究
主流人工智能研究者认为,试图通过图灵测试只是分散了更多有益研究的注意力。[61] 确实,图灵测试并不是目前许多学术或商业努力的主要焦点——正如斯图尔特·拉塞尔和彼得·诺维格所写:“人工智能研究者很少关注通过图灵测试。”[97] 这一现象有几个原因。
首先,测试程序的方式有更简单的方法。目前大多数人工智能相关领域的研究都集中在适度和具体的目标上,如物体识别或物流管理。为了测试解决这些问题的程序的智能,人工智能研究者直接给它们分配任务。斯图尔特·拉塞尔和彼得·诺维格建议可以用飞行史作为类比:飞机是通过它们的飞行效果来测试的,而不是与鸟类进行比较。“航空工程学的教材,” 他们写道,“并不把‘制造像鸽子一样飞翔的机器,能够欺骗其他鸽子’作为其领域的目标。”[97]
第二,创造生动的人类模拟本身就是一个困难的问题,而它并不需要被解决才能实现人工智能研究的基本目标。可信的人物可能在艺术作品、游戏或复杂的用户界面中有趣,但它们不属于创造智能机器的科学范畴——即,利用智能解决问题的机器。
图灵并不打算将他的想法用于测试程序的智能——他想提供一个清晰易懂的例子,以帮助讨论人工智能哲学。[98] 约翰·麦卡锡认为,我们不应对一个哲学想法最终对实践应用无用感到惊讶。他观察到,人工智能的哲学 “对人工智能研究实践的影响不太可能比科学哲学对科学实践的影响更大”。[99][100]
以语言为中心的反对意见
另一个广为人知的反对意见是,图灵测试过于专注于语言行为(即它只是一个 “基于语言” 的实验,而没有测试其他认知能力)。这一缺点缩小了考虑其他模态特定的 “智能能力” 在人类中的作用,而这些能力正是心理学家霍华德·加德纳在他的 “多元智能理论” 中提出的(语言-语言能力只是其中之一)。[101]
沉默
图灵测试的一个关键方面是,机器必须通过其言辞暴露出自己是机器。审问者必须通过正确识别机器来做出 “正确的判断”。然而,如果机器在对话中保持沉默,那么审问者只能通过计算推测来判断机器的身份。[102] 即使考虑到一个并行/隐藏的人类作为测试的一部分,也可能不会有所帮助,因为人类有时会被误识别为机器。[103]
图灵陷阱
通过专注于模仿人类,而不是增强或扩展人类能力,图灵测试有可能将研究和实现方向引向那些取代人类的技术,从而压低工人的工资和收入。随着这些工人失去经济权力,他们也可能失去政治权力,使得他们更难改变财富和收入的分配。这可能将他们困在一个不利的均衡中。埃里克·布林约尔松称之为 “图灵陷阱”[104],并认为当前有过多的激励措施来创造模仿人类的机器,而非增强人类能力的机器。
7. 变体
多年来,已经提出了许多版本的图灵测试,包括上述提到的几种。
反向图灵测试和 CAPTCHA
一种修改版的图灵测试,其中一个或多个角色之间的机器和人类的目标互换,这被称为反向图灵测试。心理分析学家威尔弗雷德·比翁(Wilfred Bion)在他的工作中暗示了这一点,[105] 他特别对 “一种心灵与另一种心灵相遇时所引发的‘风暴’” 感到着迷。在他的 2000 年书籍中,[82] 文学学者彼得·斯维尔斯基(Peter Swirski)详细讨论了他所称为斯维尔斯基测试(Swirski Test)的概念——本质上是反向图灵测试。他指出,这种方法克服了大多数甚至所有针对标准版本的反对意见。
沿着这一思路,R. D. 辛舍尔伍德(R. D. Hinshelwood)[106] 描述了心灵作为一种 “心灵识别装置”。挑战将是计算机能否确定它正在与人类还是另一台计算机互动。这是对图灵试图回答的原始问题的扩展,或许能够提供足够高的标准,以定义一种 “思考” 的机器,而这种思考通常被我们认为是具有典型人类特征的。
CAPTCHA 是一种反向图灵测试,在进行某些网站操作之前,用户会看到一个扭曲的图形图像,其中包含字母和数字,并要求用户输入它们。这是为了防止自动化系统被用来滥用该网站。其逻辑是,足够复杂的软件无法准确地读取和重现扭曲的图像(或者该软件对普通用户不可得),因此任何能够做到这一点的系统很可能是人类。
开发能够通过分析生成引擎中的模式反向破解 CAPTCHA 的软件,开始于 CAPTCHA 创建之后不久。[107] 2013 年,Vicarious 的研究人员宣布他们已经开发出一个系统,可以以 90%的准确率解决来自 Google、Yahoo! 和 PayPal 的 CAPTCHA 挑战。[108] 2014 年,Google 的工程师展示了一个系统,能够以 99.8%的准确率破解 CAPTCHA 挑战。[109] 2015 年,前 Google 点击欺诈负责人 Shuman Ghosemajumder 表示,有些网络犯罪网站会收取费用来破解 CAPTCHA 挑战,以便进行各种欺诈活动。[110]
区分语言的准确使用与实际理解
另一个变体源于对现代自然语言处理技术的担忧,这些技术在基于庞大的文本语料库生成文本方面非常成功,并且可能最终通过操控在初始训练模型中使用的单词和句子来通过图灵测试。由于提问者无法精确了解训练数据,模型可能仅仅是返回那些在庞大训练数据中以相似方式存在的句子。因此,Arthur Schwaninger 提出了一个图灵测试的变体,旨在区分仅能够使用语言的系统和真正理解语言的系统。他提出的测试是将机器置于哲学性问题的面前,这些问题不依赖任何先前的知识,但需要自我反思才能恰当地回答。[111]
领域专家图灵测试
主要文章:领域专家图灵测试 另一个变体被描述为领域专家图灵测试,其中机器的回答无法与特定领域的专家区分开。这也被称为 “费根鲍姆测试”,并由 Edward Feigenbaum 在 2003 年的论文中提出。[112]
“低级” 认知测试
Robert French(1990)认为,提问者可以通过提出揭示人类认知低级(即无意识)过程的问题,来区分人类和非人类的对话者,这些过程是认知科学研究的内容。这样的问题揭示了人类思想的具体体现细节,如果计算机无法像人类一样体验世界,就能揭示其身份。[113]
全图灵测试
“全图灵测试”[4] 是图灵测试的一个变体,由认知科学家 Stevan Harnad 提出,增加了两个传统图灵测试的要求。提问者还可以测试受试者的感知能力(要求计算机视觉)和受试者操作物体的能力(要求机器人技术)。[115]
电子健康记录
一封发表于《ACM 通讯》[116]的信件描述了生成合成患者群体的概念,并提出了一种变体的图灵测试,用于评估合成患者和真实患者之间的区别。信中指出:“在电子健康记录(EHR)背景下,尽管人类医生能够轻松区分合成生成的患者和真实的活体患者,但机器是否能具备判断这种区别的智能?” 信中进一步指出:“在合成患者身份成为公共卫生问题之前,合法的电子健康记录市场可能会通过应用类似图灵测试的技术来确保更高的数据可靠性和诊断价值。因此,任何新技术必须考虑患者的异质性,并且可能比 Allen 八年级科学测试能够评分的复杂性更高。”
最小智能信号测试
最小智能信号测试由 Chris McKinstry 提出,作为 “图灵测试的最大抽象”[117],其中仅允许二进制回答(对/错或是/否),以专注于思维能力。它消除了像人类化偏见这样的文本聊天问题,并且不要求模拟无智能的人的行为,从而允许超过人类智能的系统。每个问题必须是独立的,因此它更像是一个 IQ 测试,而不是审问。它通常用于收集统计数据,以衡量人工智能程序的表现。[118]
赫特奖
赫特奖的组织者认为,压缩自然语言文本是一个难度较大的人工智能问题,等同于通过图灵测试。数据压缩测试相较于大多数版本和变体的图灵测试有一些优势,包括:[citation needed]
- 它给出一个单一的数值,可以直接用于比较两个机器哪个 “更智能”。
- 它不要求计算机对评判者撒谎。
使用数据压缩作为测试的主要缺点是:
- 无法用这种方式测试人类。
- 不清楚在这个测试中,哪一个 “分数”(如果有的话)等同于通过人类水平的图灵测试。
基于压缩或 Kolmogorov 复杂度的其他测试
赫特奖的一个相关方法,在 1990 年代末期就已提出,是将压缩问题纳入扩展的图灵测试[119],或者通过完全基于 Kolmogorov 复杂度的测试[120]。其他相关的测试方法由 Hernandez-Orallo 和 Dowe 提出。[121]
算法 IQ,简称 AIQ,是一种尝试将 Legg 和 Hutter 的理论性普遍智能度量(基于 Solomonoff 的归纳推理)转化为一个可行的机器智能实用测试的方法。[122]
这些测试的两个主要优点是它们适用于非人类智能,并且不要求人类测试者。
埃伯特测试
图灵测试启发了电影评论家罗杰·埃伯特(Roger Ebert)在 2011 年提出的埃伯特测试。该测试评估计算机合成语音是否具备足够的音调、语调、节奏等方面的技巧,能够使人发笑。[123]
社交图灵游戏
利用大型语言模型,2023 年,研究公司 AI21 Labs 创建了一个名为 “人类还是非人类?”("Human or Not?")的在线社交实验[124][125]。该实验被超过 200 万人玩过 1000 多万次[126],是迄今为止规模最大的图灵风格实验。结果显示,32%的人无法区分人类和机器。[127][128]
8. 会议
图灵学术讨论会
1990 年是图灵《计算机与智能》论文首次发表的四十周年,这一年引发了对图灵测试的新一轮关注。该年发生了两个重要事件:其一是图灵学术讨论会(Turing Colloquium),该会议于四月在萨塞克斯大学举行,汇聚了来自不同学科的学者和研究人员,讨论图灵测试的过去、现在和未来;其二是每年举办的洛布纳奖(Loebner Prize)比赛的成立。
布雷·惠特比(Blay Whitby)列举了图灵测试历史上的四个重要转折点——1950 年《计算机与智能》的发表、1966 年约瑟夫·韦曾鲍姆(Joseph Weizenbaum)发布 ELIZA、肯尼斯·科尔比(Kenneth Colby)于 1972 年首次描述的帕里(PARRY)程序,以及 1990 年的图灵学术讨论会。[129]
2008 年 AISB 研讨会
与 2008 年在雷丁大学举行的洛布纳奖(Loebner Prize)比赛同时,人工智能与行为模拟研究协会(AISB)主办了一场为期一天的研讨会,讨论图灵测试。此次研讨会由约翰·巴恩登(John Barnden)、马克·毕晓普(Mark Bishop)、胡玛·沙阿(Huma Shah)和凯文·沃里克(Kevin Warwick)组织。[131] 演讲者包括皇家学会院长苏珊·格林菲尔德(Baroness Susan Greenfield)、塞尔梅·布林斯约德(Selmer Bringsjord)、图灵传记作者安德鲁·霍奇斯(Andrew Hodges)和意识科学家欧文·霍兰(Owen Holland)。虽然没有就标准的图灵测试达成一致意见,但布林斯约德表示,若设立一个丰厚的奖金,图灵测试可能会更快被通过。
9. 参见
- 《机械姬》(Ex Machina)(电影)
- 小说中的人工智能
- 《盲视》(Blindsight)
- 因果关系(Causality)
- 聊天机器人(Chatbot)
- ChatGPT
- 计算机游戏机器人图灵测试(Computer game bot Turing Test)
- 死互联网理论(Dead Internet theory)
- 解释(Explanation)
- 解释鸿沟(Explanatory gap)
- 功能主义(Functionalism)
- 图形图灵测试(Graphics Turing Test)
- 意识的难题(Hard problem of consciousness)
- 以艾伦·图灵命名的事物列表(List of things named after Alan Turing)
- 马克·V·谢尼(Mark V. Shaney)(Usenet 机器人)
- 身心问题(Mind-body problem)
- 镜像神经元(Mirror neuron)
- 自然语言处理(Natural language processing)
- 哲学僵尸(Philosophical zombie)
- 他人心智问题(Problem of other minds)
- 逆向工程(Reverse engineering)
- 感知(Sentience)
- SHRDLU
- 模拟现实(Simulated reality)
- 社会机器人(Social bot)
- 技术奇点(Technological singularity)
- 心智理论(Theory of mind)
- 诡异谷(Uncanny valley)
- 弗氏—坎普夫机(Voight-Kampff machine)(《银翼杀手》中的虚构图灵测试)
- Winograd 语法挑战(Winograd Schema Challenge)
10. 注释
- 图片改编自 Saygin 2000
- (Turing 1950)。图灵在 1950 年文本中集中且广泛地讨论了 “模仿游戏”(imitation game),但显然在此之后就不再使用这个术语。他提到过 “[他的]测试” 四次——三次出现在第 446-447 页,一次出现在第 454 页。他还将其称为 “实验”——一次在第 436 页,二次在第 455 页,再次在第 457 页,并使用了 “口头考试”(viva voce)一词(第 446 页),参见 Gonçalves(2023b,第 2 页)。另见下文 “版本” 部分。图灵在论文后面给出了更精确的版本:“[这些问题]等价于此,‘让我们集中注意力于某一特定数字计算机 C。是否可以通过修改这台计算机,给予它足够的存储空间,适当提高它的运算速度,并为它提供合适的程序,使得 C 能够在模仿游戏中扮演 A 的角色,而 B 的角色由人类扮演?’”(Turing 1950,第 442 页)
- 图灵最初建议使用电传打字机,这在 1950 年是为数不多的仅限文本的通信系统之一。(Turing 1950,第 433 页)
- Oppy, Graham & Dowe, David(2011)《图灵测试》,存档日期:2012 年 3 月 20 日,访问方式:Wayback Machine,斯坦福哲学百科全书。
- “The Turing Test, 1950”,turing.org.uk。艾伦·图灵互联网剪贴簿,2019 年 4 月 3 日存档,2015 年 4 月 23 日检索。
- Turing 1950,第 433 页。
- Turing 1950,第 442-454 页,并见 Russell & Norvig(2003,第 948 页),他们评论道:“图灵考察了许多对智能机器的反对意见,包括自他论文发表以来 50 年间几乎所有的反对观点。”
- Saygin 2000。
- Russell & Norvig 2003,第 2-3 页,第 948 页。
- Parsons, Paul; Dixon, Gail (2016)。《50 个你需要知道的科学概念》,伦敦:Quercus,第 65 页。ISBN 978-1-78429-614-8。
- Oxford English Dictionary, "chatbot", 第 3 版,牛津大学出版社,2010 年。访问日期:2024 年 9 月 26 日。https://www.oxfordlearnersdictionaries.com/definition/english/chatbot?q=chatbot
- Weizenbaum 1966,第 37 页。
- Weizenbaum 1966,第 42 页。
- Thomas 1995,第 112 页。
- Boden 2006,第 370 页。
- Colby 等人 1972,第 220 页。
- “Computer chatbot; Eugene Goostman; passes the Turing test | ZDNET”。ZDNet。访问日期:2024 年 9 月 26 日。
- Masnick, Mike(2014 年 6 月 9 日)。“No, A 'Supercomputer' Did NOT Pass The Turing Test for the First Time And Everyone Should Know Better”。访问日期:2024 年 9 月 26 日。
- Dan Williams(2022 年 6 月 9 日)。“人工神经网络正在朝着意识迈进,Blaise Agüera y Arcas 说”。《经济学人》。原文存档于 2022 年 6 月 9 日。访问日期:2022 年 6 月 13 日。
- Nitasha Tiku(2022 年 6 月 11 日)。“谷歌工程师认为公司的 AI 已经‘复生’”。《华盛顿邮报》。原文存档于 2022 年 6 月 11 日。访问日期:2022 年 6 月 13 日。
- Jeremy Kahn(2022 年 6 月 13 日)。“人工智能专家表示,谷歌研究人员称其聊天机器人‘具有意识’的说法荒谬,但也突显了该领域的大问题”。《财富》。原文存档于 2022 年 6 月 13 日。访问日期:2022 年 6 月 13 日。
- Biever, Celeste(2023 年 7 月 25 日)。“ChatGPT 突破图灵测试——评估 AI 的新方式竞赛已经开始”。《自然》。619(7971):686–689。Bibcode:2023Natur.619..686B。doi:10.1038/d41586-023-02361-7。PMID 37491395。原文存档于 2023 年 7 月 26 日。访问日期:2024 年 3 月 26 日。
- Scott, Cameron。“研究发现,ChatGPT 最新的机器人行为类似于人类,只是更优秀 | 斯坦福大学人文学科与科学学院”。humsci.stanford.edu。原文存档于 2024 年 3 月 26 日。访问日期:2024 年 3 月 26 日。
- Mei, Qiaozhu; Xie, Yutong; Yuan, Walter; Jackson, Matthew O.(2024 年 2 月 27 日)。“人工智能聊天机器人是否在行为上类似于人类的图灵测试”。《美国国家科学院院刊》。121(9):e2313925121。Bibcode:2024PNAS..12113925M。doi:10.1073/pnas.2313925121。ISSN 0027-8424。PMC 10907317。PMID 38386710。
- Hoy, Matthew B.(2018 年 1 月 2 日)。“Alexa, Siri, Cortana 等:语音助手简介”。《医学参考服务季刊》。37(1):81–88。doi:10.1080/02763869.2018.1404391。ISSN 0276-3869。PMID 29327988。
- “Siri vs Alexa vs Google Assistant vs Bixby: Which one reigns supreme?” 2024 年 1 月 29 日。访问日期:2024 年 9 月 26 日。
- Oxford English Dictionary, "virtual assistant", 第 3 版,牛津大学出版社,2010 年。访问日期:2024 年 9 月 26 日。https://www.oxfordlearnersdictionaries.com/definition/english/chatbot?q=chatbot
- “Cortana - Your personal productivity assistant”。微软。访问日期:2024 年 9 月 26 日。
- Withers, Steven(2007 年 12 月 11 日)。“Flirty Bot Passes for Human”,iTWire,原文存档于 2017 年 10 月 4 日,访问日期:2010 年 2 月 10 日。
- Williams, Ian(2007 年 12 月 10 日)。“Online Love Seekers Warned Flirt Bots”,V3,原文存档于 2010 年 4 月 24 日,访问日期:2010 年 2 月 10 日。
- Descartes 1996,第 34-35 页。
- 关于属性二元论的例子,请参见《Qualia》。
- 注意到物质主义并不必然意味着人工心智的可能性(例如,Roger Penrose),就像二元论并不必然排除其可能性一样。(例如,请参见《属性二元论》)。
- Ayer, A. J.(2001),“《语言、真理与逻辑》”,《自然》138(3498),企鹅出版社:140,Bibcode:1936Natur.138..823G,doi:10.1038/138823a0,ISBN 978-0-334-04122-1,S2CID 4121089【需要澄清】。
- Rapaport, W.J.(2003)。“如何通过图灵测试”,存档于 2024 年 6 月 13 日,在:Moor, J.H.(主编)《图灵测试:认知系统研究》第 30 卷,斯普林格出版社,Dordrecht。https://doi.org/10.1007/978-94-010-0105-2_9。
- Amini, Majid(2020 年 5 月 1 日)。“认知即计算:从斯威夫特到图灵 | 《人文学科公报》 | EBSCOhost”。openurl.ebsco.com。原文存档于 2024 年 6 月 13 日。访问日期:2024 年 6 月 13 日。
- Swift, Jonathan(1726)。“《格罗布丁那格之旅》第三章”。en.wikisource.org。访问日期:2024 年 6 月 13 日。
- Svilpis, Janis(2008)。“图灵测试的科幻史前”。《科学幻想研究》35(3):430–449。ISSN 0091-7729。JSTOR 25475177。
- Wansbrough, Aleks(2021)。“资本主义与迷幻屏幕:数字时代的神话与寓言”。纽约:布鲁姆斯伯里学术出版社,第 114 页。ISBN 978-1-5013-5639-1。OCLC 1202731640。
- 1956 年的达特茅斯会议被广泛认为是 “人工智能的诞生”(Crevier 1993,第 49 页)。
- McCorduck 2004,第 95 页。
- Copeland 2003,第 1 页。
- Copeland 2003,第 2 页。
- “智能机械”(1948)不是图灵发表的,直到 1968 年才出版:Evans, A. D. J.; Robertson(1968)《控制论:关键论文》,大学公园出版社。
- Turing 1948,第 412 页。
- 1948 年,图灵与他的前本科同学 DG Champernowne 合作,开始为一台尚不存在的计算机编写国际象棋程序,1952 年,由于没有足够强大的计算机来执行该程序,图灵模拟执行该程序进行了一场比赛,每走一步约耗时半小时。比赛被记录下来,程序输给了图灵的同事 Alick Glennie,尽管据说它赢了 Champernowne 的妻子。
- Turing 1948,第【需要的页面】页。
- Harnad 2004,第 1 页。
- Turing 1950,第 434 页。
- Shah & Warwick 2010a。
- Turing 1950,第 446 页。
- Turing 1952,第 524-525 页。图灵似乎没有区分 “man” 作为性别和 “man” 作为人类。在前者情况下,这一表述更接近于模仿游戏,而在后者情况下,它则更接近于当前对测试的描述。
- Searle 1980。
- 有许多反对 Searle 的中文房间论证的观点。以下是其中的一些:
- Hauser, Larry (1997),"Searle's Chinese Box: Debunking the Chinese Room Argument",《心智与机器》,7(2):199–226,doi:10.1023/A:1008255830248,S2CID 32153206。
- Rehman, Warren. (2009 年 7 月 19 日),《反对中文房间论证》,原文存档于 2010 年 7 月 19 日。
- Thornley, David H. (1997),《为什么中文房间不成立》,原文存档于 2009 年 4 月 26 日。
- M. Bishop & J. Preston(主编)(2001)《Searle 中文房间论证论文集》,牛津大学出版社。
- Saygin 2000,第 479 页。
- Sundman 2003。
- Loebner 1994。
- "人工愚蠢",《经济学人》,第 324 卷,第 7770 期,1992 年 8 月 1 日,第 14 页。
- Shapiro 1992,第 10-11 页和 Shieber 1994 等。
- Shieber 1994,第 77 页。
- "图灵测试,第 4 季,第 3 集",《科学美国前沿》,Chedd-Angier 制作公司,1993-1994 年,PBS,原文存档于 2006 年 1 月 1 日。
- "How CAPTCHAs work | What does CAPTCHA mean? | Cloudflare". 访问于 2024 年 9 月 27 日。
- "reCAPTCHA". 谷歌. 访问于 2024 年 9 月 27 日。
- "How does reCAPTCHA work? How it is triggered & bypassed". 访问于 2024 年 9 月 27 日。
- Traiger 2000。
- Saygin, Roberts & Beber 2008。
- Moor 2003。
- Traiger 2000,第 99 页。
- Sterrett 2000。
- Shah 2011。
- Genova 1994, Hayes & Ford 1995, Heil 1998, Dreyfus 1979。
- Turing 1948,第 431 页。
- Proudfoot 2013,第 398 页。
- Gonçalves 2023a。
- Gonçalves 2023b。
- Danziger 2022。
- Turing 1950,第 442 页。
- R. Epstein, G. Roberts, G. Poland(主编)《Parsing the Turing Test: Philosophical and Methodological Issues in the Quest for the Thinking Computer》。Springer: Dordrecht, Netherlands。
- Thompson, Clive (2005 年 7 月)。《The Other Turing Test》。第 13.07 期,《WIRED》杂志。原文存档于 2011 年 8 月 19 日。2021 年 9 月 10 日访问。作为一名几乎一生都在隐藏自己真实身份的同性恋者,图灵一定深刻意识到不断伪装自己真实身份的社会困难。而有趣的讽刺是,几十年来,AI 科学家们选择忽视图灵的性别扭曲测试——直到它被三名大学年龄的女性所采用。(完整版本存档于 2019 年 3 月 23 日)。
- Colby et al. 1972。
- Swirski 2000。
- Saygin & Cicekli 2002。
- Turing 1950, 见 “Critique of the New Problem” 部分。
- Haugeland 1985,第 8 页。
- "这六个学科," Stuart J. Russell 和 Peter Norvig 写道,"代表了人工智能的大部分内容。" Russell & Norvig 2003,第 3 页。
- Urban, Tim (2015 年 2 月)。"人工智能革命:我们的不朽还是灭绝"。Wait But Why。原文存档于 2019 年 3 月 23 日。2015 年 4 月 5 日访问。
- Smith, G. W. (2015 年 3 月 27 日)。"艺术与人工智能"。ArtEnt。原文存档于 2017 年 6 月 25 日。2015 年 3 月 27 日访问。
- Marcus, Gary (2014 年 6 月 9 日)。"图灵测试之后会发生什么?"《纽约客》。原文存档于 2022 年 1 月 1 日。2021 年 12 月 16 日访问。
- Shah & Warwick 2010j。
- Kevin Warwick; Huma Shah (2014 年 6 月)。"Human Misidentification in Turing Tests"。《实验与理论人工智能杂志》, 27 (2): 123–135. doi:10.1080/0952813X.2014.921734. S2CID 45773196.
- Saygin & Cicekli 2002,第 227–258 页。
- Turing 1950,第 448 页。
- 一些替代图灵测试的方法,用于评估比人类更智能的机器:
- Jose Hernandez-Orallo (2000),"Beyond the Turing Test",《逻辑、语言与信息杂志》, 9 (4): 447–466, CiteSeerX 10.1.1.44.8943, doi:10.1023/A:1008367325700, S2CID 14481982.
- D L Dowe & A R Hajek (1997),"A computational extension to the Turing Test",《澳大利亚认知科学学会第四届会议论文集》,原文存档于 2011 年 6 月 28 日,2009 年 7 月 21 日访问。
- Shane Legg & Marcus Hutter (2007),"Universal Intelligence: A Definition of Machine Intelligence" (PDF),《心智与机器》,17 (4): 391–444, arXiv:0712.3329, Bibcode:2007arXiv0712.3329L, doi:10.1007/s11023-007-9079-x, S2CID 847021,原文存档于 2009 年 6 月 18 日,2009 年 7 月 21 日访问。
- Hernandez-Orallo, J; Dowe, D L (2010),"Measuring Universal Intelligence: Towards an Anytime Intelligence Test",《人工智能》, 174 (18): 1508–1539, doi:10.1016/j.artint.2010.09.006.
- Russell & Norvig (2003,第 958–960 页) 认定 Searle 的论点与 Turing 的回答是相对应的。
- Turing 1950。
- Russell & Norvig 2003,第 3 页。
- Turing 1950,在 “模仿游戏” 这一标题下,他写道:“与其尝试这样的定义,我将用另一个问题代替,它与此问题密切相关,并且用相对明确的语言表达。”
- McCarthy, John (1996),"人工智能的哲学",《人工智能与哲学的共同点》,原文存档于 2019 年 4 月 5 日,2009 年 2 月 26 日访问。
- Brynjolfsson, Erik (2022 年 5 月 1 日),“图灵陷阱:类人人工智能的承诺与危险”,《戴达罗斯》,151 (2): 272–287. doi:10.1162/daed_a_01915。
- Gardner, H. (2011)。*Frames of Mind: 多重智能理论*。Hachette UK。
- Warwick, Kevin; Shah, Huma (2017 年 3 月 4 日),“在图灵的模仿游戏中行使第五修正案”(PDF)。《实验与理论人工智能杂志》,29 (2): 287–297. Bibcode:2017JETAI..29..287W. doi:10.1080/0952813X.2015.1132273。ISSN 0952-813X. S2CID 205634569。
- Warwick, Kevin; Shah, Huma (2015 年 3 月 4 日),“图灵测试中的人类误识别”。《实验与理论人工智能杂志》,27 (2): 123–135. doi:10.1080/0952813X.2014.921734。ISSN 0952-813X. S2CID 45773196。
- The Turing Trap。
- Bion 1979。
- Hinshelwood 2001。
- Malik, Jitendra; Mori, Greg, *Breaking a Visual CAPTCHA*,原文存档于 2019 年 3 月 23 日,2009 年 11 月 21 日访问。
- Pachal, Pete, *Captcha FAIL: Researchers Crack the Web's Most Popular Turing Test*,原文存档于 2018 年 12 月 3 日,2015 年 12 月 31 日访问。
- Tung, Liam, *Google algorithm busts CAPTCHA with 99.8 percent accuracy*,原文存档于 2019 年 3 月 23 日,2015 年 12 月 31 日访问。
- Ghosemajumder, Shuman, *The Imitation Game: The New Frontline of Security*,原文存档于 2019 年 3 月 23 日,2015 年 12 月 31 日访问。
- Schwaninger, Arthur C. (2022),"The Philosophising Machine – a Specification of the Turing Test",《哲学》,50 (3): 1437–1453,doi:10.1007/s11406-022-00480-5,S2CID 247282718。
- McCorduck 2004,第 503–505 页,Feigenbaum 2003。*专家测试*也在 Kurzweil (2005)中提到。
- French, Robert M.,“Subcognition and the Limits of the Turing Test”,《心智》,99 (393): 53–65。
- Gent, Edd (2014),*The Turing Test: brain-inspired computing's multiple-path approach*,原文存档于 2019 年 3 月 23 日,2018 年 10 月 18 日访问。
- Russell & Norvig 2010,第 3 页。
- Cacm Staff (2017)。*A leap from artificial to intelligence*,《ACM 通讯》,61: 10–11. doi:10.1145/3168260。
- *Arcondev: Message: Re: [arcondev] MIST = fog?*,原文存档于 2013 年 6 月 30 日,2023 年 12 月 28 日访问。
- McKinstry, Chris (1997),*Minimum Intelligent Signal Test: An Alternative Turing Test*,《加拿大人工智能》(41),原文存档于 2019 年 3 月 31 日,2011 年 5 月 4 日访问。
- D L Dowe & A R Hajek (1997),"A computational extension to the Turing Test",《澳大利亚认知科学学会第四届会议论文集》,原文存档于 2011 年 6 月 28 日,2009 年 7 月 21 日访问。
- Jose Hernandez-Orallo (2000),"Beyond the Turing Test",《逻辑、语言与信息杂志》,9 (4): 447–466, CiteSeerX 10.1.1.44.8943,doi:10.1023/A:1008367325700,S2CID 14481982。
- Hernandez-Orallo & Dowe 2010。
- Shane Legg 和 Joel Veness, 2011,《通用智能度量的近似》,所罗门诺夫纪念大会。
- Alex_Pasternack (2011 年 4 月 18 日),“MacBook 可能赋予 Roger Ebert 他的声音,但 iPod 拯救了他的生命(视频)”,*Motherboard*,原文存档于 2011 年 9 月 6 日,2011 年 9 月 12 日访问。他称之为 “Ebert 测试”,以此向图灵的 AI 标准致敬...
- Key, Alys (2023 年 4 月 21 日),“你能分辨出某人是人类还是 AI 吗?”,*Evening Standard*,原文存档于 2023 年 8 月 2 日,2023 年 8 月 2 日访问。
- “大规模图灵测试表明,我们仅能勉强区分 AI 与人类”,*New Scientist*,原文存档于 2024 年 7 月 22 日,2023 年 8 月 2 日访问。
- Biever, Celeste (2023 年 7 月 25 日),“ChatGPT 打破了图灵测试——评估 AI 的新方式竞争激烈”,*Nature*,619 (7971): 686–689。Bibcode:2023Natur.619..686B,doi:10.1038/d41586-023-02361-7,PMID 37491395。
- “你能分辨出人类和 AI 机器人吗?‘人类还是机器人’在线游戏揭示结果”,*ZDNET*,原文存档于 2024 年 5 月 6 日,2023 年 8 月 2 日访问。
- Press, Gil. “是 AI 聊天机器人还是人类?32% 的人分不清”,*Forbes*,原文存档于 2024 年 7 月 9 日,2023 年 8 月 2 日访问。
- Whitby 1996,第 53 页。
- Loebner 奖 2008,雷丁大学,2009 年 3 月 29 日访问[永久失效链接]。
- AISB 2008 图灵测试研讨会,人工智能与行为模拟研究学会,原文存档于 2009 年 3 月 18 日,2009 年 3 月 29 日访问。
11. 参考文献翻译
- Bion, W.S. (1979),《Making the Best of a Bad Job》,《临床研讨与四篇论文》,Abingdon: Fleetwood Press。
- Boden, Margaret A. (2006),《Mind As Machine: A History of Cognitive Science》,牛津大学出版社,ISBN 978-0-19-924144-6。
- Colby, K. M.; Hilf, F. D.; Weber, S.; Kraemer, H. (1972),“用于验证偏执过程计算机模拟的图灵类似不可区分性测试”,*人工智能*,3: 199–221,doi:10.1016/0004-3702(72)90049-5。
- Copeland, Jack (2003),Moor, James (编),《图灵测试》,《图灵测试:人工智能的难以捉摸的标准》,Springer,ISBN 978-1-4020-1205-1。
- Crevier, Daniel (1993),《人工智能:人工智能的激烈探索》,纽约:BasicBooks,ISBN 978-0-465-02997-6。
- Danziger, Shlomo (2022),“作为社会概念的智能:图灵测试的社会技术解释”,*哲学与技术*,35 (3): 68,doi:10.1007/s13347-022-00561-z,S2CID 251000575。
- Descartes, René (1996),《方法论与第一哲学沉思》,新哈文与伦敦:耶鲁大学出版社,ISBN 978-0-300-06772-9。
- Diderot, D. (2007),《哲学沉思》,《哲学沉思的附录》,[Flammarion],ISBN 978-2-0807-1249-3。
- Dreyfus, Hubert (1979),《计算机仍无法做到的事》,纽约:MIT 出版社,ISBN 978-0-06-090613-9。
- Feigenbaum, Edward A. (2003),“计算智能的一些挑战与宏大挑战”,*ACM 学报*,50 (1): 32–40,doi:10.1145/602382.602400,S2CID 15379263。
- French, Robert M. (1990),“亚认知与图灵测试的局限性”,*心智*,99 (393): 53–65,doi:10.1093/mind/xcix.393.53,S2CID 38063853。
- Genova, J. (1994),“图灵的性别猜测游戏”,*社会认识论*,8 (4): 314–326,doi:10.1080/02691729408578758。
- Gonçalves, Bernardo (2023a),“伽利略共振:实验在图灵构建机器智能中的作用”,*科学年鉴*,81 (3): 359–389,doi:10.1080/00033790.2023.2234912,PMID 37466560。
- Gonçalves, Bernardo (2023b),“图灵测试是一个思想实验”,*心智与机器*,33: 1–31,doi:10.1007/s11023-022-09616-8。
- Harnad, Stevan (2004),“注释游戏:关于图灵(1950)计算、机械和智能的讨论”,收录于 Epstein, Robert;Peters, Grace (编),《图灵测试源书:思维计算机探索中的哲学与方法问题》,Klewer,原文存档于 2011 年 7 月 6 日,2005 年 12 月 17 日访问。
- Haugeland, John (1985),《人工智能:非常的理念》,剑桥,马萨诸塞州:MIT 出版社。
- Hayes, Patrick;Ford, Kenneth (1995),“图灵测试的有害考量”,*第十四届国际人工智能联合会议论文集*(IJCAI95-1),加拿大蒙特利尔:972–997。
- Heil, John (1998),《心智哲学:当代导论》,伦敦与纽约:Routledge,ISBN 978-0-415-13060-8。
- Hinshelwood, R.D. (2001),《群体心态与拥有心智:对比翁关于群体和精神病的工作的反思》。
- Kurzweil, Ray (1990),《智能机器的时代》,剑桥,马萨诸塞州:MIT 出版社,ISBN 978-0-262-61079-7。
- Kurzweil, Ray (2005),《奇点临近》,企鹅出版社,ISBN 978-0-670-03384-3。
- Loebner, Hugh Gene (1994),“回应”,*ACM 通讯*,37 (6): 79–82,doi:10.1145/175208.175218,S2CID 38428377,原文存档于 2008 年 3 月 14 日,2008 年 3 月 22 日访问。
- McCorduck, Pamela (2004),《思考的机器》(第二版),马萨诸塞州纳塔克:A. K. Peters,ISBN 1-5688-1205-1。
- Moor, James (编) (2003),《图灵测试:人工智能的难以捉摸的标准》,多德雷赫特:Kluwer 学术出版社,ISBN 978-1-4020-1205-1。
- Penrose, Roger (1989),《皇帝的新脑:关于计算机、心智与物理法则》,牛津大学出版社,ISBN 978-0-14-014534-2。
- Proudfoot, Diane (2013 年 7 月),“重新思考图灵的测试”,*哲学杂志*,110 (7): 391–411,doi:10.5840/jphil2013110722,JSTOR 43820781。
- Russell, Stuart J.; Norvig, Peter (2003),《人工智能:现代方法》(第二版),新泽西州上萨德尔河:普伦蒂斯·霍尔,ISBN 0-13-790395-2。
- Russell, Stuart J.; Norvig, Peter (2010),《人工智能:现代方法》(第三版),新泽西州上萨德尔河:普伦蒂斯·霍尔,ISBN 978-0-13-604259-4。
- Saygin, A. P.; Cicekli, I.; Akman, V. (2000),“图灵测试:50 年后”(PDF),*心智与机器*,10 (4): 463–518,doi:10.1023/A:1011288000451,hdl:11693/24987,S2CID 990084,原文存档于 2011 年 4 月 9 日,2004 年 1 月 7 日访问。重印于 Moor (2003, pp. 23–78)。
- Saygin, A. P.; Cicekli, I. (2002),“人机对话中的语用学”,*语用学杂志*,34 (3): 227–258,CiteSeerX 10.1.1.12.7834,doi:10.1016/S0378-2166(02)80001-7。
- Saygin, A.P.; Roberts, Gary; Beber, Grace (2008),“对艾伦·图灵《计算机械与智能》一文的评论”,在 Epstein, R.; Roberts, G.; Poland, G. (编),*解析图灵测试:在寻求思维计算机中的哲学与方法论问题*,多德雷赫特,荷兰:施普林格,Bibcode:2009pttt.book.....E,doi:10.1007/978-1-4020-6710-5,ISBN 978-1-4020-9624-2,S2CID 60070108。
- Searle, John (1980),“心智、大脑与程序”,*行为与脑科学*,3 (3): 417–457,doi:10.1017/S0140525X00005756,S2CID 55303721,原文存档于 2000 年 8 月 23 日,2008 年 3 月 19 日访问。上述页码指的是该文章的标准 PDF 打印版本。另见 Searle 的原始草稿。
- Shah, Huma; Warwick, Kevin (2009a),“图灵测试中的情感:近年 Loebner 奖中的机器表现趋势下降”,在 Vallverdú, Jordi; Casacuberta, David (编),*合成情感与社交机器人研究手册:情感计算与人工智能的新应用*,信息科学,IGI,ISBN 978-1-60566-354-8。
- Shah, Huma; Warwick, Kevin (2010 年 4 月),“测试图灵的五分钟并行配对模仿游戏”,*控制论*,4 (3): 449–465,doi:10.1108/03684921011036178。
- Shah, Huma; Warwick, Kevin (2010 年 6 月),“实用图灵测试中的隐藏对话者误识别”,*心智与机器*,20 (3): 441–454,doi:10.1007/s11023-010-9219-6,S2CID 34076187。
- Shah, Huma (2011 年 4 月 5 日),*图灵被误解的模仿游戏与 IBM 沃森的成功*,原文存档于 2023 年 2 月 10 日,2017 年 12 月 20 日访问。
- Shapiro, Stuart C. (1992),“图灵测试与经济学家”,*ACM SIGART 公告*,3 (4): 10–11,doi:10.1145/141420.141423,S2CID 27079507。
- Shieber, Stuart M. (1994),“来自限制性图灵测试的教训”,*ACM 通讯*,37 (6): 70–78,arXiv:cmp-lg/9404002,Bibcode:1994cmp.lg....4002S,CiteSeerX 10.1.1.54.3277,doi:10.1145/175208.175217,S2CID 215823854,原文存档于 2008 年 3 月 17 日,2008 年 3 月 25 日访问。
- Sterrett, S. G. (2000),“图灵的两种智力测试”,*心智与机器*,10 (4): 541,doi:10.1023/A:1011242120015,hdl:10057/10701,S2CID 9600264(重印于《图灵测试:人工智能的难以捉摸的标准》,由 James H. Moor 编,Kluwer 学术出版社,2003 年)ISBN 1-4020-1205-5。
- Sundman, John (2003 年 2 月 26 日),“人工愚蠢”,*Salon.com*,原文存档于 2008 年 3 月 7 日,2008 年 3 月 22 日访问。
- Thomas, Peter J. (1995),《人机界面的社会与互动维度》,剑桥大学出版社,ISBN 978-0-521-45302-8。
- Swirski, Peter (2000),《文学与科学之间:坡、莱姆与美学、认知科学及文学知识的探索》,麦吉尔-女王大学出版社,ISBN 978-0-7735-2078-3。
- Traiger, Saul (2000),“在图灵测试中做出正确识别”,*心智与机器*,10 (4): 561,doi:10.1023/A:1011254505902,S2CID 2302024(重印于《图灵测试:人工智能的难以捉摸的标准》,由 James H. Moor 编,Kluwer 学术出版社,2003 年)ISBN 1-4020-1205-5。
- Turing, Alan (1948),“机器智能”,在 Copeland, B. Jack (编),*图灵的精华:计算机时代诞生的思想*,牛津:牛津大学出版社,ISBN 978-0-19-825080-7。
- Turing, Alan (1950 年 10 月),“计算机械与智能”,*心智*,59 (236): 433–460,doi:10.1093/mind/LIX.236.433,ISSN 1460-2113,JSTOR 2251299,S2CID 14636783。
- Turing, Alan (1952),“自动计算机能被说成是在思考吗?”,在 Copeland, B. Jack (编),*图灵的精华:计算机时代诞生的思想*,牛津:牛津大学出版社,ISBN 978-0-19-825080-7。
- Weizenbaum, Joseph (1966 年 1 月),“ELIZA——一款用于研究人机自然语言交流的计算机程序”,*ACM 通讯*,9 (1): 36–45,doi:10.1145/365153.365168,S2CID 1896290。
- Whitby, Blay (1996),“图灵测试:人工智能的最大盲道?”,在 Millican, Peter; Clark, Andy (编),*机器与思维:艾伦·图灵的遗产*,第一卷,牛津大学出版社,第 53–62 页,ISBN 978-0-19-823876-8。
- Zylberberg, A.; Calot, E. (2007),“基于遗传算法的状态导向领域中的谎言优化”,*第六届 Ibero-American 软件工程研讨会论文集*:11–18,ISBN 978-9972-2885-1-7。
12. 进一步阅读
- Cohen, Paul R. (2006),“‘如果不是图灵测试,那是什么?’”,*人工智能杂志*,26 (4),原文存档于 2017 年 2 月 15 日,2016 年 6 月 17 日访问。
- Marcus, Gary,“我还是人类吗?:研究人员需要新的方法来区分人工智能与自然智能”,*科学美国人*,第 316 卷,第 3 期(2017 年 3 月),第 58–63 页。需要多种人工智能效能测试,因为 “正如没有单一的运动能力测试一样,也不可能有单一的智能终极测试。” 其中一个测试,“构建挑战”,将测试感知和物理行为——“这两个智能行为的关键元素,在原始的图灵测试中完全没有。” 另一个提议是给机器与学童相同的标准化科学和其他学科测试。一个目前无法逾越的人工智能难题是缺乏可靠的歧义消解能力。“[几乎每个]句子[人们生成的]都有歧义,通常是多重歧义。” 一个著名的例子是 “代词歧义问题”:机器无法确定句子中代词(如 “他”、“她” 或 “它”)指代的是谁或什么。
- Moor, James H. (2001),“图灵测试的现状与未来”,*心智与机器*,11 (1): 77–93,doi:10.1023/A:1011218925467,ISSN 0924-6495,S2CID 35233851。
- Warwick, Kevin and Shah, Huma (2016),“图灵的模仿游戏:与未知的对话”,剑桥大学出版社。
13. 外部链接
- 图灵测试 — 由朱利安·瓦格斯塔夫创作的歌剧。
- 图灵测试 — 图灵测试究竟有多准确?
- Zalta, Edward N. (编辑). “图灵测试”。*斯坦福哲学百科全书*。
- 图灵测试:50 年后 评述了从 2000 年角度看图灵测试半个世纪的研究成果。
- 卡波尔与库兹韦尔之间的赌约,包括对各自立场的详细说明。
- 为什么图灵测试是人工智能的最大盲区 — Blay Witby。
- Jabberwacky.com,存档于 2005 年 4 月 11 日(通过 Wayback Machine)。一个能够从人类学习并模仿的人工智能聊天机器人。
- 《纽约时报》关于机器智能的文章,第一部分和第二部分。
- “史上第一次(限制性)图灵测试”,出现在第二季第 5 集,*科学美国人前沿,Chedd-Angier 制作公司,1991-1992 年,PBS,原文存档于 2006 年 1 月 1 日。
- 计算机科学脱离电源* 教学活动,关于图灵测试的内容。
- Wiki News: “讨论:计算机专业人士庆祝 A.L.I.C.E.的十周年纪念。”
友情链接: 超理论坛 | ©小时科技 保留一切权利