蒙特卡洛树搜索算法(理论)
贡献者: int256
蒙特卡洛树是一种不同于 Alpha-Beta 剪枝的优化 Min-Max 搜索方法。他与 Alpha-Beta 剪枝相比,更好的适用于诸如围棋一类的大型对弈游戏(即搜索空间过大,但搜索过程需要兼顾 “探索” 与 “最优化”,尽量得到全局最优解,避免陷入局部最优解),而 Alpha-Beta 剪枝的 Min-Max 搜索需要扩展几乎整个搜索树。但与 Alpha-Beta 剪枝相比,由于过程中采用蒙特卡洛方法(可以理解为抽样检测),搜索的结果并不保证一定是最优解。
值得一提的是,蒙特卡洛树搜索算法不是蒙特卡洛算法。
蒙特卡洛树搜索限定于解决 Combinatorial Game,例如一般的围棋、象棋等等。
1. UCB 算法
UCB,upper confidence bound,置信度上界,是蒙特卡洛树搜索中启发式搜索的一种常用方式,下面先来考察 UCB 算法。
UCB 算法是用来评估多臂老虎机类型的问题的,这个问题一般描述如下:
你面前有 $n$ 个老虎机,每个老虎机都有一个拉杆,每次可以拉下一个老虎机的拉杆,一共可以拉 $A\times n$ 下拉杆($A \gg n$)。每次拉下拉杆都有一定的概率获得 $1$ 块钱,每个拉杆获得奖金的概率不同(这概率是不知道的)。我们的目标是最小化后悔(regret),后悔值是在这 $A\times n$ 次拉下的过程中积累的,每次的后悔值是拉下最优拉杆获得奖金的概率减去本次拉下的拉杆的获奖概率,当然后悔值在拉完这一共 $A\times n$ 次后才知道。当然由于我们知道之前拉拉杆的过程,我们也可以积累一些经验(experience)。
这个问题就是一个典型的要兼顾 “探索” 和 “优化” 的例子。我们需要给每次拉拉杆时的每个拉杆赋分,选择分值最高的拉杆拉下(如果遇到分值一样则随机选取一个)。一个容易想到的赋分方式是: $$\text{Score} = P_{maybe} + \lambda u ~~$$ 其中,$P_{maybe}$ 是根据历史拉拉杆情况估计的这个拉杆会获奖的概率(用于 “优化”),而 $u$ 则衡量不确定度(用于兼顾 “探索”)。$\lambda$ 是某权重因子。
首先我们考虑 Chernoff-Hoeffding Bound。
考虑假设在标准正态分布下,$\sigma^2=1$(这最终还可以体现在 $\lambda$ 中,现在不妨先让 $\sigma^2=1$),再令 $\delta = \exp\left(-nu^2/2\right)$,可以发现 $u=\sqrt{[2 \ln\left(1/\delta\right) ]/n}$。实际应用中一般可以令 $1/\delta=N$,$N$ 为目前的总轮数。所以置信上界就是 $\widetilde \mu + \sqrt{\left(2 \ln N \right)/n}$。
对于实际应用情况,一般取一 $\lambda$ 使置信上界为
适用于树搜索的 UCB
采用 UCB 的蒙特卡洛树(一般这种对于树的 UCB 还被称为 UCT,Upper Confidence Bounds for Trees)搜索是一种(类)启发式的搜索,大体思路是:在选择子结点的时候,
- 优先考虑未搜索过的;
- 如果都搜索过就根据给每个结点的 “赋分” 来选择,这个 “赋分” 是与这个结点的最终获胜概率正相关、与这个子结点访问的的次数负相关的。
我们可以看到第 $2$ 条就是为了兼顾 “探索” 与 “优化”。与最终获胜概率正相关为了保证 “优化”、与访问次数负相关为了兼顾 “探索”。
2. 蒙特卡洛树搜索算法
下面利用一张经典的图片讲解蒙特卡洛树搜索算法的步骤。
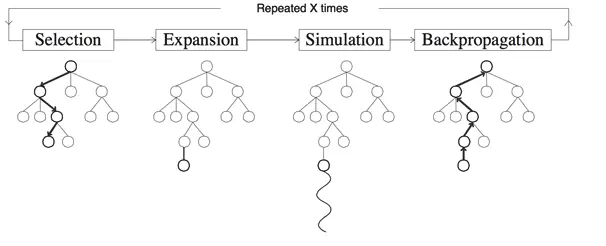
可以发现整体过程主要是重复以下 $4$ 步:
- 选择(Selection):根据刚才提到的 UCT 算法,找到一个叶子结点。
- 拓展(Expansion):对当前叶子结点进行扩展。
- 模拟(Simulation):对当前叶子结点的局势进行蒙特卡洛模拟。
- 反向传播(Back propagation):根据蒙特卡洛模拟的结果更新 UCT 的信息与记录的分数。
一般的来说,蒙特卡洛树搜索的过程中 $2$ 与 $3$ 两操作是类似于交替进行的。对于全新的叶子结点(未经 Expansion),我们进行 Simulation 操作,如果已经被 Simulation 过,我们进行 Expansion 操作。
对于反向传播操作,从当前叶子结点到根结点的这条链上的所有结点的信息。
Simulation 操作在实现中又被称为 Rollout。一般是使用一个棋力不强(甚至可以是较弱)的模拟走子程序,一路走到底,模拟出胜负。原因是这样棋力弱的程序一般耗时很短,可以在单位时间内搜索更多,性能更良好。像 AlphaGo 这样的程序在这一步利用了策略网络,虽然更慢了,但是棋力更强,使得结果更准确。
3. 代码实现
蒙特卡洛树搜索算法可以用于实现类似于下面的这种问题。
例 1
使用蒙特卡洛树搜索算法实现一个机器 vs. 机器的 Tic-Tac-Toe 井字棋对战游戏。Tic-Tac-Toe 有以下规则:
- 井字棋棋盘是 $n \times n$ 的正方形网格棋盘,例如下面是一个有一些棋子的 $7 \times 7$ 的棋盘:
 图 2:棋盘例
图 2:棋盘例 - 游戏的下法是有 $ \boldsymbol\times $、$\bigcirc$ 两方,每次都可以在没有棋子的正方形内部落子。输赢定义为:最先有连续 $m$ 个我方棋子出现的一方获胜。
- 连续的定义是:横向、纵向,或两个 $45^\circ$ 对角线方向。
你需要使得以下内容是可以自定义的:
- $n$,即棋盘大小可以自定义。
- $m$,即输赢的(棋子连续数)条件可以自定义。
- 先下棋的一方可以自定义。也就是谁第一步下棋可以自定义。
这是一个工程问题,不用考虑时间限制。你需要输出机器对战的中间过程、最终的结果棋盘与谁赢得了这场对战。
对于这个例题,实现代码可以参考文章《蒙特卡洛树搜索算法(实现 TicTacToe 机-机对战)》,该篇文章使用 python 3.7 + numpy 实现。建议读者先自己尝试实现,遇到困难再学习这篇文章。
友情链接: 超理论坛 | ©小时科技 保留一切权利