拓扑排序
贡献者: 待更新
(本文根据 CC-BY-SA 协议转载自原搜狗科学百科对英文维基百科的翻译)
在计算机科学中,有向图的拓扑排序或拓扑排序是其顶点的线性排序,使得对于每个从顶点 u 到顶点 v 的有向边,代表 $u$ 在排序中位于 $v$ 之前。例如,图的顶点可以表示要执行的任务,而边可以表示一个任务必须先于另一个任务执行的约束;在这个应用中,拓扑排序只是任务的有效序列。当且仅当图没有有向循环时,即当它是有向无环图时,才可能是拓扑排序。任何 DAG 都至少有一个拓扑排序,并且存在用于在线性时间内构造任何 DAG 的拓扑排序的算法。
1. 例子
拓扑排序的典型应用是根据作业或任务的相关性来安排它们的顺序。作业由顶点表示,如果作业 x 必须在作业 y 开始之前完成,则从 x 到 y 有一条边(例如,洗衣服时,洗衣机必须在我们将衣服放入烘干机之前完成)。然后,拓扑排序给出了执行作业的顺序。拓扑排序算法的一个密切相关的应用是在 20 世纪 60 年代早期被首次研究的,其背景是在项目管理中用于调度的 PERT 技术(Jarnagin 1960);在这个应用中,图的顶点代表项目的决定性事件,边代表必须在一个决定性事件和另一个之间执行的任务。拓扑排序构成了寻找项目关键路径的线性时间算法的基础,一系列决定性事件和任务控制着整个项目进度的长度。
在计算机科学中,这种类型的应用出现在指令调度、在电子表格中重新计算公式值时对公式单元格求值的排序、逻辑合成、确定在 makefiles 中执行的编译任务的顺序、数据序列化以及解决链接器中的符号依赖性等方面。它还用于决定在数据库中以何种顺序加载带有外键的表。
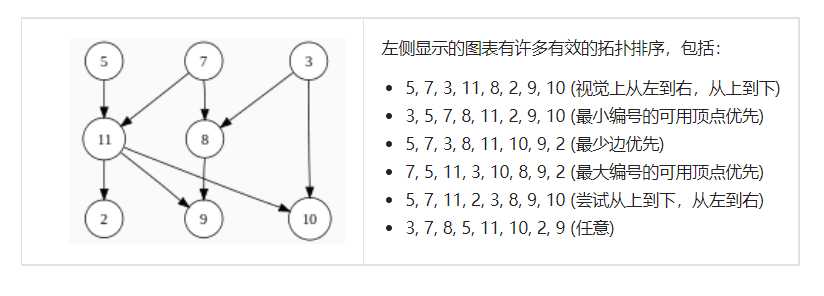
2. 算法
拓扑排序的常用算法的运行时间是节点数加上边数的线性渐进,$O(|V|+|E|)$.
2.1 卡恩算法
卡恩(1962)首先描述了其中一种算法,它通过选择与最终拓扑排序相同顺序的顶点来工作。首先,找到一个没有引入边的 “起始节点” 列表,并将它们插入到集合 S 中;非空无环图中必须至少存在一个这样的节点。然后:
L ← 包含排序好的元素的空列表
S ← 没有输入边的所有节点的集合
while S is non-empty do
remove a node n from S
add n to tail of L
for each node m with an edge e from n to m do
remove edge e from the graph
if m has no other incoming edges then
insert m into S
if graph has edges then
return error (图表至少有一个环)
else
return L (拓扑排序的顺序)
反映出结果排序的非唯一性,结构 S 可以是简单的集合、队列或堆栈。根据节点 n 从集合 S 中移除的顺序,会生产不同的解决方案。卡恩算法的一个变体在字典上打破了联系,这是科菲曼-格雷厄姆并行调度和分层图形绘制算法的一个关键组成部分。
2.2 深度优先搜索
拓扑排序的另一种算法是基于深度优先搜索。该算法以任意顺序遍历图中的每个节点,启动深度优先搜索,当该搜索到达自拓扑排序开始以来已经被访问过的任何节点或者该节点没有输出边(即叶节点)时终止:
L ← 包含已排序节点的空列表
while exists nodes without a permanent mark do
select an unmarked node n
visit(n)
function visit(node n)
if n has a permanent mark then return
if n has a temporary mark then stop (not a DAG)
mark n with a temporary mark
for each node m with an edge from n to m do
visit(m)
remove temporary mark from n
mark n with a permanent mark
add n to head of L
2.3 并行算法
在并行随机存取机器上,可以使用多项式数量的处理器在 0(log2n)时间内构造拓扑排序,将问题归入复杂性类 NC2 (Cook 1985)。一种方法是用最小加矩阵乘法,用最大化代替最小化,对给定图的邻接矩阵进行多次对数平方。得到的矩阵描述了图中最长的路径距离。根据顶点最长输入路径的长度对顶点进行排序,进而构造拓扑排序(Dekel,Nassimi & Sahni 1981)。
3. 最短路径查找的应用
拓扑排序也可用于通过加权有向无环图快速计算最短路径。假设 V 是这样一个图中顶点的列表,按拓扑顺序排列。然后,以下算法计算从某个源顶点 $s$ 到所有其他顶点的最短路径:[1]
- Let d be an array of the same length as V; this will hold the shortest-path distances from s. Set d[s] = 0, all other d[u] = ∞.
- Let p be an array of the same length as V, with all elements initialized to nil. Each p[u] will hold the predecessor of u in the shortest path from s to u.
- Loop over the vertices u as ordered in V, starting from s:
- For each vertex v directly following u (i.e., there exists an edge from u to v):
- Let w be the weight of the edge from u to v.
- Relax the edge: if $d[v] > d[u] + w$, set
- $d[v] \longleftarrow d[u] + w$,
- $p[v] \longleftarrow u$.
在 $n$ 个顶点和 $m$ 条边的图上,该算法花费 $\Theta(n + m)$,即线性时间。[1]
4. 独特性
如果拓扑排序具有排序顺序中所有连续顶点对由边连接的性质,那么这些边在 DAG 中形成有向哈密顿路径。如果哈密顿路径存在,拓扑排序顺序是唯一的;没有其他顺序符合路径上的边。相反,如果拓扑排序不形成哈密尔顿路径,则 DAG 将具有两个或更多有效的拓扑排序,因为在这种情况下,总是有可能通过交换没有通过边彼此连接的两个连续顶点来形成第二有效排序。因此,有可能在线性时间内测试是否存在唯一的排序,以及哈密尔顿路径是否存在,尽管哈密尔顿路径问题对于更一般的有向图来说具有 NP-难度(Vernet & Markenzon 1997)。
5. 与偏序的关系
拓扑序也与数学中偏序的线性扩展概念密切相关。在高级术语中,有向图和偏序之间有一个联系。[2]
偏序集只是一组对象以及 “$\leq$” 不等式关系的定义,满足自反性 $(x\leq x)$、反对称(如果 $(x\leq y)$ 和 $(y\leq x)$ 则 x = y)和传递性(如果 $(x\leq y)$ 和 $(y\leq x)$ 则 $x\leq x$ 的公理。一个全序关系是偏序的,如果,对于集合中的每两个对象 $x$ 和 $y$,$(x\leq y)$ 或 $(y\leq x)$。全序关系在计算机科学中一个被人熟知的存在就是需要执行比较排序算法的比较运算符。对于有限集合,全序关系可以用对象的线性序列来标识,其中每当第一个对象在顺序上位于第二个对象之前时,“$\leq$” 关系为真;比较排序算法可以用于以这种方式将全序关系转换成序列。偏序的线性扩展和全序相容,也就是说,如果偏序关系中 $(x\leq y)$,那么全序关系中 $(x\leq y)$。
只要存在从 $x$ 到 $y$ 的有向路径,也就是说,每当 $y$ 从 $x$ 可达时,就可以通过让对象集成为 DAG 的顶点,并为任意两个顶点 $x$ 和 $y$ 定义 $(x\leq y)$ 为真,来定义任意 DAG 的偏序;根据这些定义,DAG 的拓扑序与这个偏序的线性扩展是一样的。相反,有限集合上的任何偏序都可以定义为 DAG 中的可达性关系。一种方法是定义一个 DAG,该 DAG 对于部分有序集中的每个对象都有一个顶点,对于 $(x\leq y)$ 的每对对象都有一个边 $xy$。一般来说,这会产生边较少的 Dag,但是这些 Dag 中的可达性关系仍然是相同的偏序。通过使用这些构造,可以使用拓扑排序算法来寻找偏序的线性扩展。
6. 参考文献
[1] ^Cormen, Thomas H.(英语:Thomas H. Cormen); Leiserson, Charles E. ; Rivest, Ronald L.; Stein, Clifford (2009) [1990]. Introduction to Algorithms (3rd ed.). MIT Press and McGraw-Hill. pp. 655–657. ISBN 0-262-03384-4.CS1 maint: Multiple names: authors list (link).
[2] ^Spivak, David I. (2014). Category Theory for the Sciences. MIT Press..