条件生成对抗网络
贡献者: xzllxls
条件生成对抗网络(Conditional Generative Adversarial Nets, cGAN)是生成对抗网络的条件版本。可以通过简单地向模型输入数据来构建。
在无条件的生成模型中,对于生成的数据没有模式方面的控制,很有可能造成模式坍塌。而条件生成对抗网络的思想就是通过输入条件数据,来约束模型生成的数据的模式。输入的条件数据可以是类别标签,也可以是训练数据的一部分,又甚至是不同模式的数据[1]。因此,条件生成对抗网络的输入主要有两部分,一是条件数据,二是随机噪音。
与原始的生成对抗网络相同,条件生成对抗网络也是玩的是双人最小最大游戏,其目标函数为:
条件生成对抗网络基本结构,如图 1 所示。
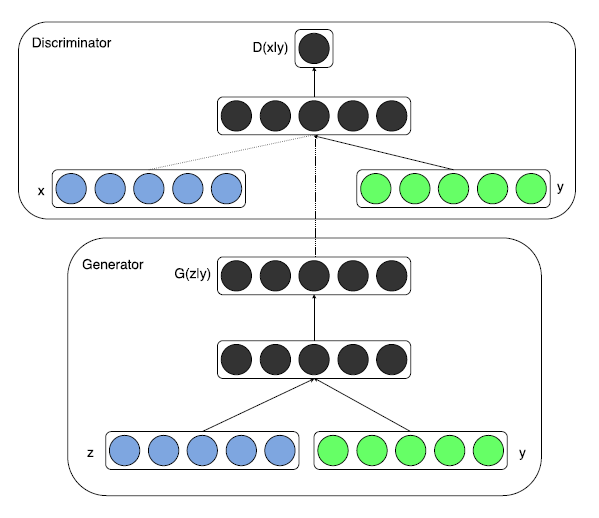
图 2 表示了用 MINST 数据集训练的条件生成对抗网络生成数字的部分实验结果。每一行均以对应的数字标签作为输入条件。

条件生成对抗网络的条件数据取决于实际应用场景,在不同应用场景下,可以有所不同。比如,对于文本转换成图像(text-to-image)的任务,条件数据是文本;对于图像转换成图像(image-to-image)的任务,条件数据则是图像。例如,图 2 展示的是一个用于从黑白素描图片转换成彩色照片任务的条件生成对抗网络结构。
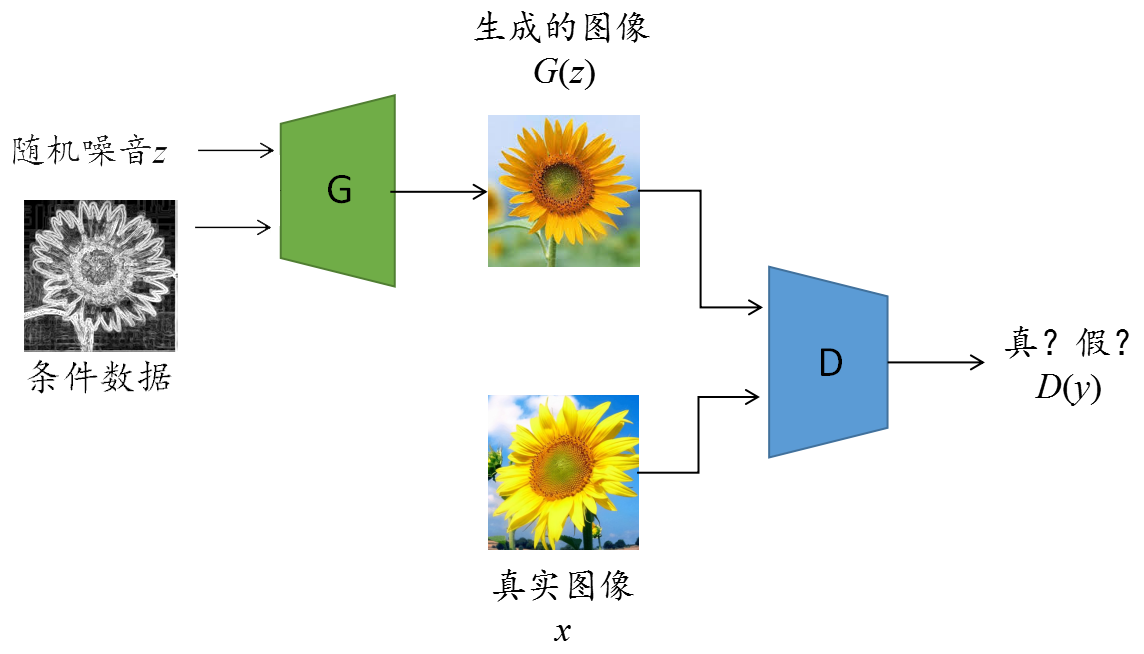
Isola 等人[2]使用条件生成对抗网络研究是图像到图像的转换任务,提出 pix2pix 模型。具体任务是把结构简单的草图生成对应的照片级的图像。研究人员采用的是配对数据来训练模型,也就是说一张草图与一张照片配对成一个图片对,每次迭代时,都将相应的图片对送入模型训练。模型的输入数据包含两部分:随机噪音和草图(作为条件数据)。
该工作的目标函数也包含两个部分,一是对抗损失,二是传统的像素级别图像相似度评价指标(例如 L1 损失、L2 损失等)。如果只使用对抗损失,也能够生成清晰的图片,但图片可能某些部分变化过大,甚至是产生不太合理的内容,从而导致图片失真。因此,加入传统损失的作用是使得模型产生的图片不至于偏离真实图片过大。数学表达式如下所示:
条件对抗损失:
可以参考以下示例 Python 代码来建立一个条件生成对抗网络的模型。本例使用的是 Tensorflow 框架。
import tensorflos as tf
def build_model(self):
"""
A表示输入域,B表示输出域。
该方法的功能是建立一个把数据从域A转换到域B的条件生成对抗网络模型。
"""
# 1. 建立一个传送数据的节点。
# self.batch_size表示批次大小;self.image_size表示图像尺寸
# self.input_c_dim表示输入数据的通道数。
# self.output_c_dim表示输出数据的通道数。
self.real_data = tf.placeholder(tf.float32,
[self.batch_size, self.
image_size, self.image_size,
self.input_c_dim + self.output_c_dim],
name='real_A_and_B_images')
# 2. 建立输入和输出数据的节点。
# self.real_B是喂送域B数据的节点;self.real_A是喂送域A数据的节点。
self.real_B = self.real_data[:,:,:,:self.input_c_dim]
self.real_A = self.real_data[:,:,:,self.input_c_dim:self.input_c_dim
+ self.output_c_dim]
# 3. 建立生成器
# self.fake_B是网络产生的域B数据的节点。
# self.generator是建立生成器的方法。
self.fake_B = self.generator(self.real_A)
# 4. 建立判别器
self.real_AB = tf.concat([self.real_A, self.real_B], 3)
self.fake_AB = tf.concat([self.real_A, self.fake_B], 3)
self.D, self.D_logits = self.discriminator(self.real_AB, reuse=False)
self.D_, self.D_logits_ = self.discriminator(self.fake_AB, reuse=True)
# 5. 定义判别器损失
self.d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=self.D_logits,
labels=tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
logits=self.D_logits_,
labels=tf.zeros_like(self.D_)))
# 6. 定义生成器损失
# tf.nn.sigmoid_cross_entropy_with_logits方法的功能是先计算Sigmoid激活函数值,再计算交叉熵。
self.g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
logits=self.D_logits_,
labels=tf.ones_like(self.D_)))
+self.L1_lambda * tf.reduce_mean(
tf.abs(self.real_B - self.fake_B))
参考文献:
- M. Mirza and S. Osindero, “Conditional generative adversarial nets,” arXiv preprint arXiv:1411.1784, 2014.
- P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1125–1134.