Julia 再说数组的构造
贡献者: xzllxls
本文授权转载自郝林的 《Julia 编程基础》。原文链接:第 10 章 容器:数组(下)。
10.6 再说数组的构造
现在,让我们再次转到数组值的构造这个主题上来。我们还需要知道一些关于它的方式方法。
除了直接用字面量编写(即一般表示法)或者调用构造函数,我们还可以使用另外一种方式产生数组值。这种方式被称为数组推导。先来看一个简单的例子:
julia> array_comp1 = [e*2 for e in 1:6]
6-element Array{Int64,1}:
2
4
6
8
10
12
julia>
与数组的一般表示法一样,数组推导式(comprehensions)在最外层也有一对中括号。但与之不同的是,后者的中括号内并没有元素值的排列。取而代之的是,一个针对元素值的加工表达式(以下简称加工表达式)和一个简写形式的 for 语句(以下简称 for 从句)。
在上例中,e*2 就是加工表达式,而 for e in 1:6 则是 for 从句,它们之间由空格分隔。加工表达式会逐个地处理 for 从句迭代出的每一个值,也就是在后者迭代时先后赋予迭代变量 e 的那些值。这些经过处理的值都将被包含在新数组中。Julia 会严格按照迭代的顺序排列它们。由此可见,上面的代码就相当于:
julia> array_comp1 = [];
julia> for e in 1:6
append!(array_comp1, e*2)
end
julia> array_comp1
6-element Array{Any,1}:
2
4
6
8
10
12
julia>
顺便说一下,其中的函数 append! 的功能是,将它的第二个参数值追加进由第一个参数代表的列向量内。第二个参数值可以是一个单一值,也可以是一个列向量或元组。如果是后者,那么它里面的所有元素值都会被依次地追加进第一个参数值内。
数组推导式中的被迭代对象也可以是一个多维的数组。这时,新数组的维数和长度都仍然会依从于被迭代的对象。同时,加工表达式也仍然会分别处理被迭代对象中的每一个元素值。示例如下:
julia> array_comp2 = [e*2 for e in [[1,2] [3,4] [5,6]]]
2×3 Array{Int64,2}:
2 6 10
4 8 12
julia>
不过,新数组的元素类型却可以与被迭代对象的元素类型不同。更明确地说,它只由加工表达式决定。加工表达式的结果类型就将是新数组的元素类型。例如:
julia> array_comp3 = [Float32(e*2) for e in [[1,2] [3,4] [5,6]]]
2×3 Array{Float32,2}:
2.0 6.0 10.0
4.0 8.0 12.0
julia>
这里的加工表达式的结果类型显然是 Float32。所以,新数组的元素类型也会是 Float32。
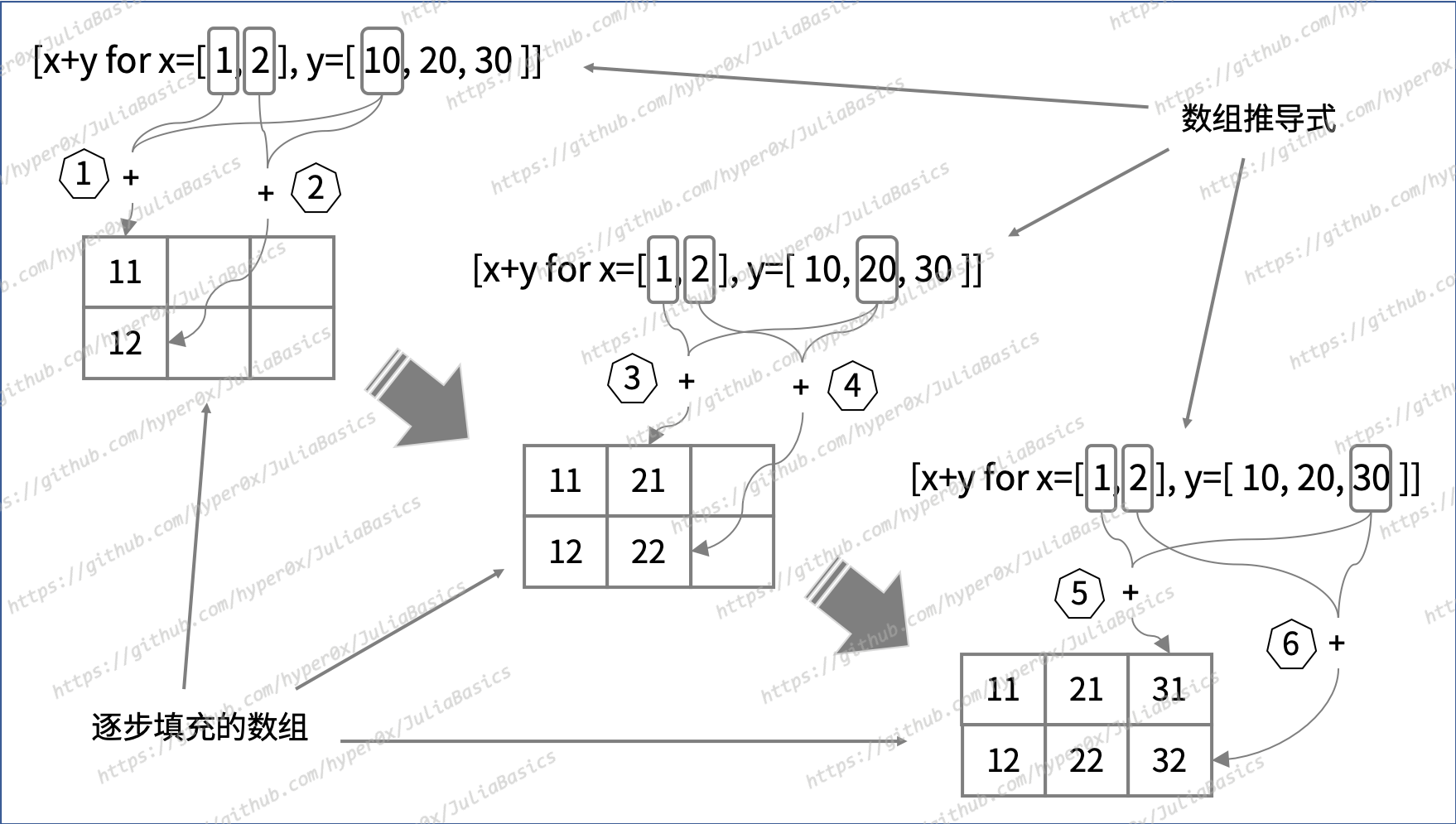
另外,数组推导式中也可以同时存在多个被迭代对象。在这种情况下,它的 for 从句的写法会有所不同。下面是一个例子:
julia> array_comp4 = [x+y for x=1:2, y=[10,20,30]]
2×3 Array{Int64,2}:
11 21 31
12 22 32
julia>
这里有三点需要注意:
1. 这时的 for 从句的写法不再是 “for <迭代变量> in <被迭代对象>”,而是 “for <迭代变量1>=<被迭代对象1>, <迭代变量2>=<被迭代对象2>, ...”。请注意,其中的等号的含义是 “每次迭代均赋值”,而不是单纯的 “赋值”。另外,英文逗号在这里起到了分隔的作用。实际上,即使只有一个被迭代对象,我们也可以使用 “for <迭代变量>=<被迭代对象>” 这种写法。
2. 这时的 for 从句并不会同时迭代两个被迭代对象。它会先去迭代右边数的第一个对象,并在迭代右边数的第一个对象一次之后去遍历右边数的第二个对象一次。然后,再迭代一次第一个对象并再遍历一次第二个对象。如此交替往复,直到完全迭代完右边数的第一个对象为止。这里所说的遍历是指,从头到尾地迭代一遍。
3. 新数组中的元素值数量会等于各个被迭代对象的元素值数量的乘积,而新数组的维数则会等于各个被迭代对象的维数之和。而且,第一个被迭代对象(假设为 N 维数组)中的各个维度的长度会决定新数组中前 N 个维度的长度,而第二个被迭代对象(假设为 M 维数组)中各个维度的长度则会决定新数组中第 N+1 个至第 N+M 个维度的长度,以此类推。最后,Julia 总会把加工表达式产出的一个个值按照线性索引的顺序依次地放到新数组中的各个元素位置上。
对于第 3 个注意事项,我们再来看一个例子:
julia> array_comp5 = [x+y for x=[[1,2] [3,4]], y=10:10:30]
2×2×3 Array{Int64,3}:
[:, :, 1] =
11 13
12 14
[:, :, 2] =
21 23
22 24
[:, :, 3] =
31 33
32 34
julia>
在这个例子中,第一个被迭代对象是 [[1,2] [3,4]]。它有 2 个维度,且每一个维度的长度都是 2。因此,其元素值的总数就是 4。第二个被迭代对象是 10:10:30,它是 StepRange 类型的,表示的是一个从 10 开始、到 30 结束且相邻值间隔为 10 的数值序列。显然,此序列只有 1 个维度,且长度是 3。所以,新数组中的元素值共有 12 个,并且它是一个 2×2×3 的三维数组。我们通过上面的 REPL 环境的回显内容就可以对此进行验证。
如果我们想把迭代出并加工好的一个个值都塞到一个一维的数组中,那么就需要换一种写法。请看下面的示例:
julia> array_comp6 = [x+y for x=[[1,2] [3,4]] for y=10:10:30]
12-element Array{Int64,1}:
11
21
31
12
⋮
33
14
24
34
julia>
在这里,for 从句的写法变成了 “for <迭代变量1>=<被迭代对象1> for <迭代变量2>=<被迭代对象2>”。也就是说,我只是把其中的英文逗号 “, ” 换成了 “ for ”(两边都有空格)。一定要注意,虽然这样的改动很小,但却会明显改变迭代的次序。
你可能也看出来了,后面这种写法会使得 for 从句先去迭代左边数的第一个对象,而不是右边数的第一个对象。更具体地说,它每迭代一次左边数的第一个对象就会遍历一次左边数的第二个对象。
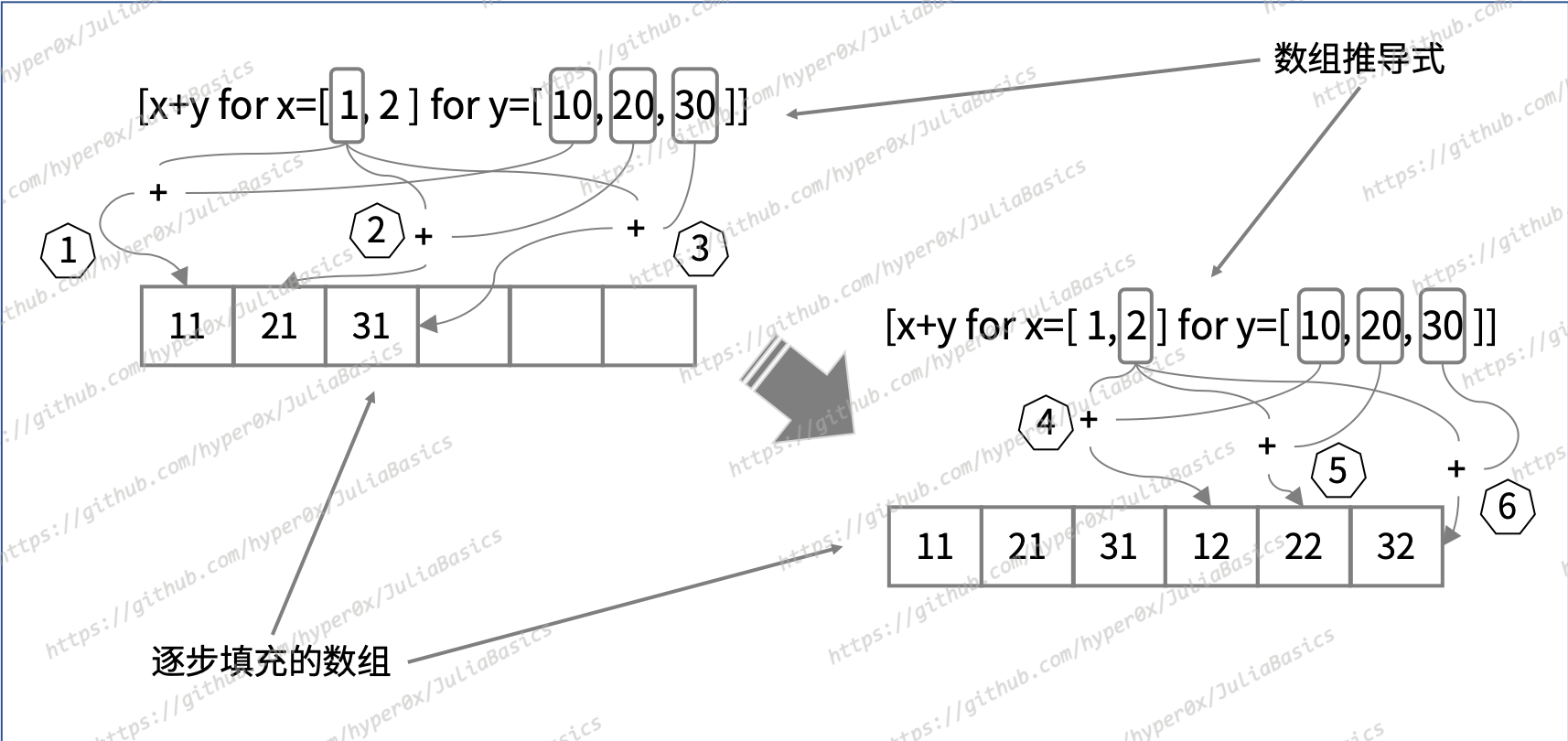
实际上,这与嵌套在一起的多条 for 语句所表现出的行为是一样的。
另外,数组推导式还有一种机制可以对 for 从句迭代出的元素值进行过滤。它只会把满足既定条件的那些元素值传给加工表达式。这种机制是用另一种从句表达的,即:if 从句。
这里所说的 if 从句实质上是 if 语句的简写形式。与 for 语句一样,if 语句也是控制代码的执行流程的一种方式。简单来说,它可以表达 “如果满足这里的条件,就执行语句中的代码” 的语义。类似的,数组推导式中的 if 从句表达的语义是 “如果满足这里的条件,就把当前的元素值传给加工表达式”。我们来看一个例子:
julia> array_comp7 = [x+y for x=[[1,2] [3,4]], y=10:10:30 if isodd(x)]
6-element Array{Int64,1}:
11
13
21
23
31
33
julia>
这个例子中的数组推导式是基于 array_comp5 的那个数组推导式变化而来的。我没有修改已有的 for 从句和加工表达式,只是在 for 从句的右边添加了一条 if 从句而已。请注意,这两条从句之间需要由空格分隔。
这条 if 从句有两个部分,即:代表 if 从句起始的 if 关键字和代表条件表达式的 isodd(x)。显然,它表达的条件是,从第一个对象迭代出的元素值是奇数。从数组推导式返回的结果我们也可以看出,新数组中的元素值都是奇数。这正是因为,新元素值的个位是由第一个被迭代对象中的元素值决定的。另外,你应该也看到了,新数组是一个一维的数组。实际上,只要加入了 if 从句,数组推导式的求值结果就只可能是一维数组。
我们在前面说过,数组推导式在最外层会有一对中括号。不过,这对中括号也可以没有。但是这时就不能叫它数组推导式了,而应该叫做生成器表达式(generator expressions)。
与数组推导式不同,生成器表达式既不能独立存在也不能被赋给某个变量。它只能被作为参数值传入某个函数。为了避免歧义和提高可读性,我们总是应该用一对圆括号包裹生成器表达式。请看下面的示例:
julia> reduce(*, (x for x=1:5))
120
julia> xs = [x for x=1:5]; reduce(*, xs)
120
julia>
这个例子中的前一行代码包含了一个生成器表达式,而后一行代码包含了一个数组推导式。这两行代码做了同样的事情,那就是计算了从 1 到 5 的阶乘。虽然前一行代码更短,但是显然后一行代码的可读性更好,同时也更容易修改。那么使用生成器表达式的优势到底在哪里呢?
实际上,使用生成器表达式的唯一优势就在于,它可以在不预先生成数组结构和存储元素值的情况下,进行基于那些元素值的计算。再简单一点说就是,它比较节省内存空间。我们来用代码观测一下:
julia> @allocated reduce(*, (x for x=1:10))
0
julia> @allocated reduce(*, [x for x=1:10])
160
julia>
宏 @allocated 的功能是,观测和显示后续代码在执行的过程中用掉的内存空间,单位是字节。可以看到,这里的生成器表达式在执行的过程中并没有申请新的内存空间,而使用数组推导式实现同样的功能则要用掉 160 个字节。
当然了,程序的好坏肯定不能单凭是否节省内存空间来衡量。如果我们观测程序的执行时间(可以用 @timev 宏),那么就会发现:在稍微复杂一些的情况下,生成器表达式通常还不如相应的数组推导式执行速度快。再加上可读性和可扩展性方面的考虑,我建议你知道有这样一种代码编写方式就可以了,不要迷恋这种看上去很潇洒的写法,尤其不要滥用。写程序还是要优先关注可读性和可扩展性。而且,在内存如此廉价的当代,我们在考虑程序的性能时应该更加关注执行的时间而不是占用的内存。
言归正传。我们再来概括一下。数组推导式能够产生新的数组值。它可以由三个部分组成,按照从左到右的顺序,即:加工表达式、for 从句和 if 从句。前两个部分是必须要有的,而最后一个部分是可选的。
数组推导式产生新元素值的过程简单来说是这样的:for 从句从被迭代对象那里迭代出元素值,若有 if 从句则要对元素值进行条件判断和过滤,最后把(满足条件的)元素值传给加工表达式以生成新的元素值。数组推导式会根据被迭代对象的基本要素以及 for 从句的编写形式和 if 从句的有无来创建新的数组结构,并按照线性索引的顺序依次地把一个个新生成的元素值放到这个数组结构中的相应元素位置上。
总之,数组推导式是继一般表示法和构造函数之后的第三大数组构造方式。而且,它的功能更为强大,在灵活性方面也明显胜过后两者。