Julia 的三种主要类型
贡献者: xzllxls
本文授权转载自郝林的 《Julia 编程基础》。原文链接:第 4 章 类型系统。
4.4 三种主要类型
如果以是否可以被实例化来划分的话,Julia 中的类型可以被分为两大类:抽象类型和具体类型。而具体类型还可以再细分。我们先从抽象类型说起。
4.4.1 抽象类型
抽象类型不能被实例化。正因为如此,抽象类型只能作为类型图中的节点,而不能作为终端。如果把类型图比喻成一棵树的话,那么抽象类型只能是这棵树的树干或枝条,而不可能是树上的叶子。即使是 Union{} 这个特殊的层类型,也无法成为叶子并与一般的值和变量扯上关系。
有了抽象类型,我们就可以去构造自己的类型层次结构。比如,由 AbstractString 类型延伸出一些特殊的字符串类型,以便适配一些具体的情况。又比如,从直接继承自 Any 的某个类型开始,一步步构建和扩展我们自己的类型(子)图,从而描绘出一个面向某个领域的数据类型体系。
另外,抽象类型让我们在编写数据结构和算法时不必指定具体的类型。在很多时候,具体类型就意味着严格的限制。这可能会让程序更加稳定,但也可能会使程序失去必要的灵活性。当有了抽象类型和类型层次结构,我们就可以根据自己的需要去权衡稳定性与灵活性之间的关系了。我们在前面编写的那个 sum1 函数就是一个很好的例子。
下面,我们一起来看看怎样定义一个抽象类型。这种定义的一般语法是这样的:
abstract type <类型名> end
或
abstract type <name> <: <超类型名> end
注意,其中的成对尖括号及其包含的内容是需要我们替换掉的。
这里有两种形式。它们都以多词关键字 abstract type 开头,并后接类型的名称。不同的是,第一种形式没有显式地指定它的超类型,而直接以 end 结尾了。在这种情况下,这个被定义的类型的超类型就是 Any。而第二种形式在类型名和 end 之间插入了操作符 <: 和超类型名。我们之前说过,这个操作符在这里表示 “A 直接继承自 B”,或者说 “A 是 B 的直接子类型”。其中 A 代表该操作符左侧的类型,而 B 则代表操作符右侧的类型。
我们在前面展示过的抽象类型 Signed 的定义使用的就是第二种形式。Signed 类型直接继承了 Integer 类型:
abstract type Signed <: Integer end
如果我们把焦点扩散开来,就会发现这只是数值类型层次结构中的一小段。下面是数值类型子图的示意。
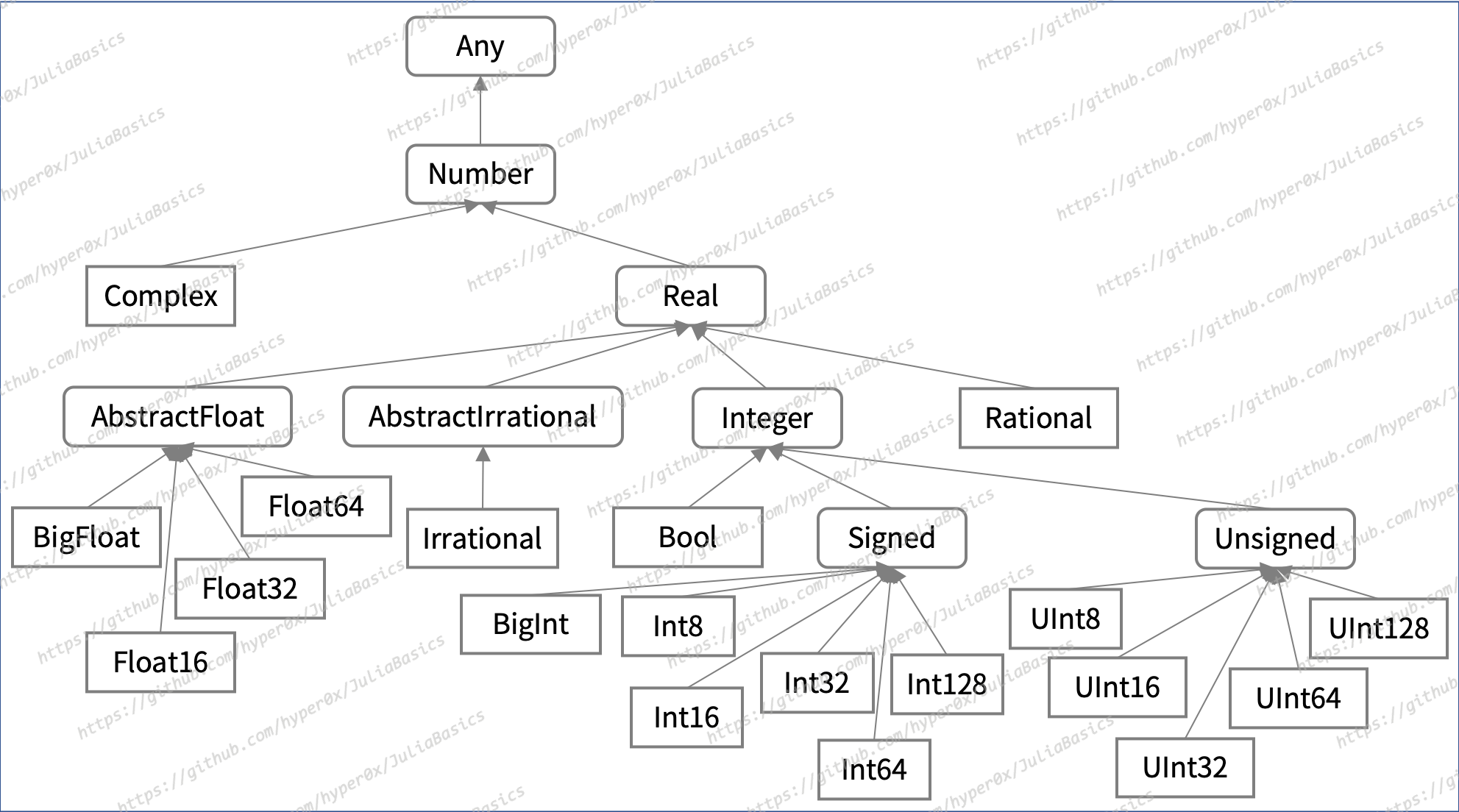
图中由圆角矩形包裹的类型都是抽象类型,而由直角矩形包裹的类型都是具体类型。再次强调,只有具体类型(如 Float32、Bool、Int64 等)才可能被实例化,而抽象类型(如 Real、Integer、Signed 等)一定不能被实例化。不过一个值却可以是某个抽象类型的实例。比如,10 这个值就是 Signed、Integer 和 Real 类型的实例。原因是这几个抽象类型都是具体类型 Int64 的超类型。
我们可以说,抽象类型就是 Julia 类型图中的支柱。没有它们,整个类型层次结构就不复存在。其根本原因是,具体类型不能像抽象类型那样被继承。也就是说,具体类型只能是类型图中的终端或树上的叶子。
顺便提一句,我们可以使用 isabstracttype 函数来判断一个类型是否属于抽象类型,还可以用 isconcretetype 函数判断一个类型是否属于具体类型。显然,对于同一个类型,这两个函数总会给出相反的结果。
4.4.2 原语类型
原语类型是一种具体类型。它的结构相当简单,仅仅是一个扁平的比特(bit)序列。我们在前面提到的数值类型中有很多都属于原语类型,具体如下:
- 浮点数类型:
Float16、Float32和Float64 - 布尔类型:
Bool - 有符号整数类型:
Int8、Int16、Int32、Int64和Int128 - 无符号整数类型:
UInt8、UInt16、UInt32、UInt64和UInt128
除此之外,Char 类型也属于原语类型。所以,Julia 预定义的原语类型一共有 15 个。
原语类型的定义方式与抽象类型的很相似。只不过它以多词关键字 primitive type 开头,而不是以 abstract type 开头。我们之前提到过 Int64 类型的定义,它是这样的:
primitive type Int64 <: Signed 64 end
注意,在这个定义的超类型名 Signed 和关键字 end 之间有一个数字 64。这个数字代表的就是该类型的比特序列的长度。或者说,它代表的是该类型的值需要占据的存储空间的大小,单位是比特。为了与值的显示长度区分开,我们通常把这个数字称为类型的宽度。实际上,这里的宽度已经体现在 Int64 类型的名称中了。
由此,我们可以得知,Int8 与 UInt8 的宽度是相同的,Int16 与 UInt16 的宽度也是相同的。以此类推。虽然宽度相同,但由于它们的名称不同,所以还是不同的类型。更何况,它们的含义也是不一样的。
Bool 类型和 Char 类型的宽度都没有体现在名称上。但通过其含义,我们可以倒推出它们的宽度。Bool 是用于存储布尔值的类型。布尔值总共才有两个,即:true 和 false。因此按理说使用一个比特来存储就足够了。但由于计算机内存的最小寻址单位是字节(即 8 个比特),更小的存储空间既不利于内存寻址也无益于性能优化,所以布尔值最少也要用 8 个比特来存储。至于 Char,它的值代表单个 Unicode 字符。由于一个 Unicode 字符最多也只会占用 4 个字节,所以把 Char 类型的宽度设定为 32 个比特就足够了。
顺便说一下,如果我们想在程序中获得一个类型的宽度,那么可以使用 sizeof 函数,就像这样:
julia> sizeof(Bool)
1
julia> sizeof(Char)
4
julia>
该函数会返回一个 Int64 类型的结果值。但要注意,从这里得到的类型宽度的单位是字节,而不是比特。
与很多其他的编程语言都不同,Julia 允许我们定义自己的原语类型。如此一来,我们就可以在一个固定大小的空间中存放自己的比特级数据了。例如,我们可以定义这样一个原语类型:
primitive type MyUInt64 <: Unsigned 64 end
原语类型 MyUInt64 直接继承自 Unsigned 类型,所以它的值可以被用来存储无符号整数。又因为它的宽度是 64,所以其值需要占据的存储空间是 8 个字节。
不过,要想让这个类型真正实用,我们还需要编写更多的代码。对于这些代码,你目前阅读起来可能会有些难。所以我把它们存放到了相对路径为 src/ch04/primitive/main.jl 的源码文件中。如果你现在就对此感兴趣,可以打开这个文件看一看。其中的注释会帮助你更好地理解代码。
4.4.3 复合类型
复合类型也是一种具体类型。它的结构可以很简单,也可以相对复杂。这完全取决于我们的具体定义。我们可以在定义一个复合类型的时候为它添加若干个有名称、有类型的字段,以满足我们对数据结构的要求。这里的字段也是由一个标识符代表的。它与变量很类似,只不过它只能存在于复合类型的内部。对于一个复合类型的字段,我们只能通过其实例才能访问到。
在 Julia 中,复合类型是唯一一种可以由我们完全掌控的类型,同时也是最常用的一种类型。很多编程语言也都有类似的类型。有的语言把它的实例称为对象,而有的语言把它的实例称为结构体。在这里,为了体现这种类型的特点,我们把 Julia 中的复合类型的实例也称为结构体(但它们也都是对象)。在一些编程语言中(比如 Java 和 Golang),每个复合类型都可以关联一些方法。而在 Julia 中,复合类型是不可以关联任何方法的。对此,我们已经在前面有所提及。这种设计可以让程序变得更加灵活。
4.4.3.1 定义
复合类型的定义需要由关键字 struct 开头,并且再加上一个类型的名称作为第一行。与其他的很多定义一样,复合类型的定义也需要以独占一行的 end 作为结尾。下面是一个简单的例子:
julia> struct User
name::String
reg_year::UInt16
extra
end
julia>
我定义了一个名为 User 的类型。它包含了 3 个字段,分别是 name、reg_year 和 extra。每个字段的定义都独占一行。其中,name 代表姓名,是 String 类型的,而 reg_year 代表注册年份,是 UInt16 类型的。至于 extra,我打算用它来存储一些额外的信息,具体是什么我现在还不能确定。所以我没有为这个字段添加类型标注。这样的话,这个字段的类型将会是 Any 类型。也就是说,我可以赋给它任何类型的值。
4.4.3.2 实例化
复合类型的实例化需要用到构造函数(constructor)。不过,我们并不用自己手动编写,这与原语类型一样。一个使用示例如下:
julia> u1 = User("Robert", 2020, "something")
User("Robert", 0x07d0, "something")
julia>
可以看到,构造函数是与对应的类型同名的,并且我是按照 User 类型中字段定义的顺序来为构造函数传入参数值的。
Julia 会为每一个复合类型都自动生成两个构造函数。它们也被称为默认的构造函数。第一个构造函数的所有参数都一定是 Any 类型的,我们称之为泛化的构造函数。这种构造函数可以让我们用任何类型的参数值去尝试构造 User 类型的实例。不过,这不一定会成功。原因是,当参数类型不匹配时,Julia 会尝试使用 convert 函数把参数值转换成对应字段的那个类型的值。如果这种转换失败,那么对复合类型的实例化也将失败。例如:
julia> u2 = User("Robert", 2020.1, "something")
ERROR: InexactError: UInt16(2020.1)
# 省略了一些回显的内容。
julia>
在复合类型的第二个默认的构造函数中,每一个参数的类型都一定会与对应字段的类型一致。这个函数中不会有任何的参数类型转换。如果像下面这样调用,就一定会用到该函数:
julia> u2 = User("Robert", UInt16(2020), "something")
User("Robert", 0x07d0, "something")
julia>
真的是这样吗?空口无凭,我们怎么验证这种规则呢?这就需要用到一个名叫 @which 的宏了。至于什么是宏,你现在可以简单地把它理解为一种特殊的函数。它可以像操纵数据那样去操纵代码。我们在使用宏的时候需要在其名称之前插入一个专用的符号 @。拿 @which 来说,这个宏的本名其实是 which。
怎样使用 @which 宏呢?很简单,我们可以把前面示例中的等号右边的代码作为参数值传给它,就像这样:
julia> @which User("Robert", UInt16(2020), "something")
User(name::String, reg_year::UInt16, extra) in Main at REPL[1]:2
julia>
可以看到,我只用空格分隔了宏名称和它的参数值。我们当然也可以像调用普通函数那样用圆括号包裹住参数值。但由于这里传入的是一段代码,所以为了清晰我选用了第一种方式。
我们现在来看 REPL 环境回显的内容。显然,User(name::String, reg_year::UInt16, extra) 正是我们在前面描述的第二个默认的构造函数。它的每个参数的类型都与对应字段的类型相一致。前面那句话由此得到了证实。
相对应的,当我们给 u1 赋值时,等号右边的代码实际上调用的是第一个默认的构造函数。证据如下:
julia> @which User("Robert", 2020, "something")
User(name, reg_year, extra) in Main at REPL[1]:2
julia>
关于复合类型的构造函数,我们就先介绍到这里。在后面讲函数和方法的时候,我们还会说到它。另外,在本教程的最后一部分,我们还会专门讨论宏和元编程。
4.4.3.3 字段的访问
我们再来说一下字段的访问方式。我在刚开始讲复合类型的时候说过:只有通过其实例才能访问到其中的字段。那具体应该怎样做呢?
其实很简单,通过一个英文点号就可以做到。这个英文点号在这里被称为选择符。我们可以用它来选择复合类型实例中的某个字段。示例如下:
julia> u2.name
"Robert"
julia> Int16(u2.reg_year)
2020
julia>
这里的代码 u2.name 也常被称为选择表达式。注意,虽然我们可以像上面那样访问到 u2 的字段,但是却不能用这种方式修改它们的值:
julia> u2.name = "Eric"
ERROR: setfield! immutable struct of type User cannot be changed
# 省略了一些回显的内容。
julia>
依据错误信息,我们得知这个 User 类型的结构体竟然是不可变的!没错,我们定义的所有复合类型的实例都是不可变的。你会觉得这很不合常理吗?虽然不同于其他的一些编程语言的做法,但这样做是非常有好处的。具体如下:
- 提高了程序的安全性。我们完全不用担心因操作失误而造成的数据更改。尤其是在与其他的代码共享数据的时候。在其他的编程语言中,我们往往需要通过控制访问权限来做到这一点。
- 提高了程序的性能。Julia 对不可变的实例会有很多优化的手段。比如,当它们在函数间传递的时候并不会造成多余的内存分配。因为对于不可变的值,通常只存一份就足够了。
- 可以减少我们的心智负担。这很好理解,我们肯定不用担心一个不可变的值会在某个时刻突然发生变化。而且,我们可以完全确定,一个复合类型的所有实例都是不可变的。这可以省去不少用于检查的代码。
不过要注意,虽然复合类型的实例本身是不可变的,但如果它包含了某种可变类型(比如数组)的字段,那么它还是可以被改变的。复合类型的实例本身只能保证,可变类型的字段始终只会引用同一个可变值。关于这一点,我们需要在定义复合类型的时候就考虑清楚。
4.4.3.4 可变的复合类型
Julia 当然允许我们定义可变的复合类型。定义的方式与通常的复合类型定义非常相似。只需要把单词关键字 struct 替换为多词关键字 mutable struct 就可以了。显然,其中的 “mutable” 是唯一的关键。
例如,我们可以定义一个可变的复合类型 Person,然后构造一个此类型的实例,并随意地修改其中的字段值。代码如下:
julia> mutable struct Person
name::String
age::UInt8
extra
end
julia> p1 = Person("Robert", 30, "something")
Person("Robert", 0x1e, "something")
julia> p1.age = 37
37
julia> Int8(p1.age)
37
julia>
此外,可变的复合类型与不可变的复合类型还有一个很重要的不同,那就是:
- 对于可变的复合类型,即使两个实例中对应字段的值都相同,这两个实例也是不同的。例如:
julia> p2 = Person("Robert", 37, "something"); p1 === p2 false julia> - 对于不可变的复合类型,只要两个实例中对应字段的值都相同,这两个实例就是相同的。例如:
julia> u1 === u2 true julia>
操作符 === 用于比较两个值是否完全相同。对于可变的值,这个操作符会比较它们在内存中的存储地址。对于不可变的值,该操作符会逐个比特地比较它们。此类操作的结果总会是一个 Bool 类型的值。
因此,p1 和 p2 不相同的原因是,它们是被分别构造的,它们的值被存储在了不同的内存地址上。而 u1 和 u2 显然是同一个值,因为它们的内容完全一样。
到这里,我们已经介绍了 Julia 中 3 种主要的类型,即:抽象类型、原语类型和复合类型。它们可以构建起一幅拥有层次结构的类型图。抽象类型不能被实例化,但可以被继承。它们是类型图的支柱。没有它们,整个类型层次结构就不复存在。这是由于具体类型虽然可以被实例化,但却不能被继承。
原语类型和复合类型都属于具体类型。它们都可以由我们自己定义。但用得最多的还是复合类型。注意,复合类型在默认情况下是不可变的。我们只有使用多词关键字 mutable struct 进行定义,才能让复合类型成为可变类型。
最后,再提示一点,Julia 中的类型继承只支持单继承。也就是说,一个类型的超类型只可能有一个。