计算机视觉(综述)
贡献者: 待更新
本文根据 CC-BY-SA 协议转载翻译自维基百科相关文章。
计算机视觉任务包括获取、处理、分析和理解数字图像的方法,以及从现实世界中提取高维数据,以产生数值或符号信息,例如决策的形式。[1][2][3][4] 在这个上下文中,“理解” 意味着将视觉图像(即输入到视网膜的图像)转化为世界的描述,这些描述对思维过程有意义,并能够引发适当的行动。这种图像理解可以看作是通过几何学、物理学、统计学和学习理论的帮助,使用模型从图像数据中解开符号信息。
计算机视觉这一科学学科关注的是从图像中提取信息的人工系统背后的理论。图像数据可以呈现多种形式,如视频序列、来自多个摄像头的视角、来自 3D 扫描仪的多维数据、来自 LiDAR 传感器的 3D 点云,或医学扫描设备的数据。计算机视觉的技术学科旨在将其理论和模型应用于计算机视觉系统的构建。
计算机视觉的子学科包括场景重建、物体检测、事件检测、活动识别、视频追踪、物体识别、3D 姿态估计、学习、索引、运动估计、视觉伺服、3D 场景建模和图像修复。
1. 定义
计算机视觉是一个跨学科领域,研究如何让计算机从数字图像或视频中获得高级理解。从工程的角度来看,它旨在自动化人类视觉系统能够完成的任务。[5][6][7] “计算机视觉关注的是从单张图像或图像序列中自动提取、分析和理解有用信息。它涉及开发理论和算法基础,以实现自动的视觉理解。”[8] 作为一门科学学科,计算机视觉关注的是从图像中提取信息的人工系统背后的理论。图像数据可以有多种形式,如视频序列、来自多个摄像头的视角,或来自医学扫描仪的多维数据。[9] 作为一门技术学科,计算机视觉旨在将其理论和模型应用于计算机视觉系统的构建。机器视觉则指的是一个系统工程学科,特别是在工厂自动化的背景下。近年来,计算机视觉和机器视觉这两个术语在一定程度上趋于融合。[10]: 13
2. 历史
在 20 世纪 60 年代末,计算机视觉在那些开创人工智能的大学中开始发展。它的目标是模仿人类视觉系统,作为赋予机器人智能行为的垫脚石。[11] 1966 年,人们认为这一目标可以通过一个本科生的暑期项目来实现,即将相机连接到计算机,并让计算机 “描述它所看到的内容”。[12][13][14]
当时,计算机视觉与数字图像处理领域的主要区别在于,它希望从图像中提取三维结构,目的是实现完整的场景理解。1970 年代的研究为许多如今存在的计算机视觉算法奠定了早期基础,包括从图像中提取边缘、标记线条、非多面体和多面体建模、将物体表示为小结构的相互连接、光流和运动估计等。[11]
接下来的十年,计算机视觉的研究逐渐转向更加严格的数学分析和定量方法。这些研究包括尺度空间的概念、从各种线索(如阴影、纹理和焦点)推断形状,以及称为 “蛇形模型” 的轮廓模型。研究人员还意识到,许多这些数学概念可以在同一个优化框架内处理,类似于正则化和马尔可夫随机场的应用。[15] 到了 1990 年代,一些之前的研究主题变得比其他主题更为活跃。投影三维重建方面的研究加深了对相机标定的理解。随着相机标定优化方法的出现,人们意识到,很多这些想法已经在摄影测量学中的束调整理论中被探索过。这催生了多张图像的稀疏三维重建方法。同时,图割算法的变种被用来解决图像分割问题。本十年还标志着统计学习技术首次被应用于图像中的人脸识别(参见 Eigenface)。到 1990 年代末,计算机图形学与计算机视觉领域的互动大幅增加,这带来了图像基础渲染、图像变形、视角插值、全景图像拼接以及早期的光场渲染技术。[11]
近年来,基于特征的方法与机器学习技术及复杂优化框架结合使用,得到了复兴。[16][17] 深度学习技术的进步为计算机视觉领域注入了新的活力。深度学习算法在多个标准计算机视觉数据集上的准确性,已经超越了以前的方法,这些任务包括分类、分割和光流等。[19]
3. Related fields
固态物理

固态物理是与计算机视觉密切相关的另一个领域。大多数计算机视觉系统依赖于图像传感器,这些传感器检测电磁辐射,通常表现为可见光、红外光或紫外光。传感器的设计基于量子物理学。光与表面的相互作用过程通过物理学来解释。物理学还解释了光学行为,而光学是大多数成像系统的核心部分。复杂的图像传感器甚至需要量子力学来提供对图像形成过程的完整理解。[11] 此外,物理学中的各种测量问题也可以通过计算机视觉来解决,例如流体中的运动。
神经生物学
神经生物学对计算机视觉算法的发展产生了深远影响。在过去的一个世纪里,科学家对人类和各种动物的眼睛、神经元和大脑结构进行了广泛研究,重点是视觉刺激的处理。这些研究为理解自然视觉系统如何解决某些与视觉相关的任务提供了粗略而复杂的描述。这些成果促成了计算机视觉的一个子领域,旨在设计人工系统,模仿生物系统在不同复杂度层次上的处理和行为。此外,计算机视觉中一些基于学习的方法(例如,基于神经网络和深度学习的图像与特征分析与分类)也有其神经生物学背景。由福岛邦彦在 1970 年代开发的神经网络——新认知论(Neocognitron)就是一个早期的例子,展示了计算机视觉如何直接借鉴神经生物学,特别是初级视觉皮层的工作原理。
一些计算机视觉研究方向与生物学视觉研究密切相关——事实上,就像许多人工智能研究与人类智能以及利用存储知识来解释、整合和利用视觉信息的研究紧密相连一样,生物学视觉领域研究和模型化了人类及其他动物的视觉感知生理过程。与此不同,计算机视觉则开发并描述了实现人工视觉系统的软件和硬件中的算法。生物学与计算机视觉之间的跨学科交流对两者都取得了有益的成果。
信号处理
与计算机视觉相关的另一个领域是信号处理。许多用于处理单变量信号(通常是时间信号)的方法,可以自然地扩展到计算机视觉中处理二维或多变量信号。然而,由于图像的特定性质,计算机视觉中有许多方法在单变量信号处理领域中是没有对等方法的。加上信号的多维性,这就定义了信号处理中的一个子领域,作为计算机视觉的一部分。
机器人导航
机器人导航有时涉及自主路径规划或机器人系统在环境中导航的推理。[22] 要在环境中导航,需要对这些环境有详细的理解。关于环境的信息可以通过计算机视觉系统提供,该系统作为视觉传感器,提供关于环境和机器人自身的高层次信息。
视觉计算
视觉计算是一个通用术语,指所有与三维建模的图形需求相关的计算机科学学科,这些需求扩展到所有计算科学学科。虽然这与微服务的软件下载视觉学紧密相关,视觉计算还包括以下子领域的专业化:计算机图形学、图像处理、可视化、计算机视觉、计算成像、增强现实和视频处理,这些领域进一步延伸到设计计算。视觉计算还包括模式识别、人机交互、机器学习、机器人学、计算机仿真、隐写术、安全可视化、空间分析、计算视觉学和计算创意等方面。核心挑战是视觉信息的获取、处理、分析和呈现。应用领域包括工业质量控制、医学图像处理和可视化、测量、multimedia 系统、虚拟遗产、电影和电视中的特效,最终是计算机游戏,这些都与用户体验设计的视觉模型密切相关。总之,这还包括生成性人工智能中的大型语言模型(LLM),用于开发围绕科学仪器(如微服务)仿真研究的计算科学。尤其是在具身代理与生成性人工智能之间的研究仿真中,这些都是为视觉计算设计的。因此,这一领域也延伸到通过计算科学中互联研究的可视化技术所解决的科学需求的多样性。
其他领域
除了上述关于计算机视觉的观点,许多相关的研究课题也可以从纯粹数学的角度进行研究。例如,计算机视觉中的许多方法是基于统计学、优化或几何学的。最后,计算机视觉领域的一个重要部分专注于其实现方面;即如何在各种软件和硬件组合中实现现有方法,或者如何修改这些方法以在不损失过多性能的情况下提高处理速度。计算机视觉还被应用于时尚电商、库存管理、专利检索、家具和美容行业。[23]
区分
与计算机视觉最密切相关的领域包括图像处理、图像分析和机器视觉。这些领域的技术和应用范围有很大的重叠。这意味着,所使用和发展的基本技术是相似的,可以理解为这些领域只是在名称上有所不同。另一方面,研究小组、科学期刊、会议和公司通常需要明确将自己归类为其中一个领域,因此,各种区分这些领域的特征也被提出。在图像处理中,输入和输出都是图像,而在计算机视觉中,输入可以是图像或视频,输出可能是增强的图像、对图像内容的理解,甚至是基于这种理解的计算机系统行为。
计算机图形学通过 3D 模型生成图像数据,而计算机视觉通常通过图像数据生成 3D 模型[24]。目前也有将这两个学科结合的趋势,例如增强现实中探索的内容。
以下是一些相关的区分,但不应视为普遍接受的标准:
- 图像处理和图像分析通常集中在二维图像上,如何将一个图像转换为另一个图像,例如通过像素级操作(如对比度增强)、局部操作(如边缘提取或噪声去除)或几何变换(如图像旋转)。这一特征表明,图像处理/分析不需要对图像内容做出假设,也不提供关于图像内容的解释。
- 计算机视觉包括从二维图像进行三维分析。这分析的是投影到一张或多张图像上的三维场景,例如如何从一张或多张图像中重建三维结构或其他信息。计算机视觉通常依赖于关于图像中描绘场景的更复杂的假设。
- 机器视觉是应用一系列技术和方法,进行基于图像的自动检查、过程控制和机器人引导[25],主要用于工业应用[21]。机器视觉通常侧重于应用,特别是在制造业中,例如基于视觉的机器人和视觉检查、测量或捡拾系统(如箱体捡拾[26])。这意味着图像传感器技术和控制理论通常与图像数据处理结合使用,以控制机器人,并强调通过硬件和软件中的高效实现进行实时处理。它还意味着,在机器视觉中,外部条件(如光照)通常比一般计算机视觉中更容易控制,这使得可以使用不同的算法。
- 还有一个叫做成像的领域,主要集中在生成图像的过程中,但有时也涉及图像的处理和分析。例如,医学成像包括大量关于医学应用中图像数据分析的工作。卷积神经网络(CNNs)的进展提高了在医学图像中准确检测疾病的能力,特别是在心脏病学、病理学、皮肤病学和放射学中。[27]
- 最后,模式识别是一个使用各种方法从信号中提取信息的领域,主要基于统计方法和人工神经网络[28]。该领域的一个重要部分是将这些方法应用于图像数据。
摄影测量学与计算机视觉也有重叠,例如,立体摄影测量与计算机立体视觉。
4. 应用
计算机视觉的应用范围从工业机器视觉系统等任务开始,比如检查在生产线上的瓶子快速通过,直到研究人工智能以及能够理解周围世界的计算机或机器人。计算机视觉和机器视觉领域有显著的重叠。计算机视觉涵盖了自动图像分析的核心技术,广泛应用于许多领域。机器视觉通常指的是将自动图像分析与其他方法和技术结合,提供自动化检查和机器人引导的过程,主要用于工业应用。在许多计算机视觉应用中,计算机是预先编程来解决特定任务的,但基于学习的方法现在越来越常见。计算机视觉的应用示例包括:
- 自动检查,例如,制造应用中的自动检查;
- 辅助人类进行识别任务,例如,物种识别系统;[29]
- 控制过程,例如,工业机器人;
- 检测事件,例如,用于视觉监控或人数统计,例如,在餐饮行业;
- 交互,例如,作为计算机与人类交互设备的输入;
- 监测农业作物,例如,开发了一种开源视觉变换器模型[30],帮助农民以 98.4%的准确
- 率自动检测草莓疾病。[31]
- 建模物体或环境,例如,医学图像分析或地形建模;
- 导航,例如,由自动驾驶车辆或移动机器人完成;
- 组织信息,例如,用于图像和图像序列的数据库索引;
- 在 3D 坐标中追踪表面或平面,以实现增强现实体验。
医学
最突出的一应用领域是医学计算机视觉或医学图像处理,其特点是从图像数据中提取信息以诊断患者。例如,肿瘤、动脉硬化或其他恶性变化的检测,以及各种牙科病理的诊断;器官尺寸、血流等的测量也是另一个例子。它还通过提供新信息来支持医学研究,例如关于大脑结构或医疗治疗质量的信息。计算机视觉在医学领域的应用还包括增强人类解读的图像——例如超声波图像或 X 光图像——以减少噪声的影响。
机器视觉
计算机视觉的第二个应用领域是在工业中,有时被称为机器视觉,其中信息被提取以支持生产过程。一个例子是质量控制,其中细节或最终产品被自动检查以发现缺陷。最常见的检查领域之一是半导体行业,其中每一个单独的硅片都被测量和检查,以发现不准确或缺陷,防止计算机芯片进入市场时出现无法使用的情况。另一个例子是测量细节的定位和方向,以供机器人手臂拾取。机器视觉也广泛应用于农业过程,用于去除大宗物料中不需要的食品,这一过程称为光学分选。
军事
军事应用可能是计算机视觉最大的领域之一。显而易见的例子包括敌军士兵或车辆的检测以及导弹制导。更先进的导弹制导系统将导弹发送到一个区域,而不是特定的目标,目标选择在导弹到达该区域时根据本地获取的图像数据进行。在现代军事概念中,如 “战场感知”,各种传感器,包括图像传感器,提供了关于战斗场景的丰富信息,可以用于支持战略决策。在这种情况下,自动数据处理用于减少复杂性,并通过融合来自多个传感器的信息来提高可靠性。
自动驾驶车辆

其中一个较新的应用领域是自动驾驶车辆,包括潜水器、陆地车辆(如带轮的小型机器人、汽车或卡车)、空中车辆和无人驾驶航空器(UAV)。这些车辆的自动化程度从完全自动驾驶(无人驾驶)车辆到依靠计算机视觉支持驾驶员或飞行员的车辆不等。完全自动驾驶的车辆通常使用计算机视觉进行导航,例如用于了解自身位置或绘制环境地图(SLAM)、检测障碍物。它还可以用于检测某些特定任务事件,例如无人机寻找森林火灾。支持系统的例子包括汽车中的障碍警告系统、车辆中的摄像头和激光雷达传感器,以及用于飞机自主着陆的系统。一些汽车制造商已经展示了自动驾驶系统的原型。军事领域中也有大量自动驾驶车辆的例子,从先进的导弹到用于侦察任务或导弹制导的无人机。太空探索也已经在使用计算机视觉的自动驾驶车辆中取得进展,例如美国 NASA 的 “好奇号” 和中国 CNSA 的 “玉兔二号” 探测车。
触觉反馈
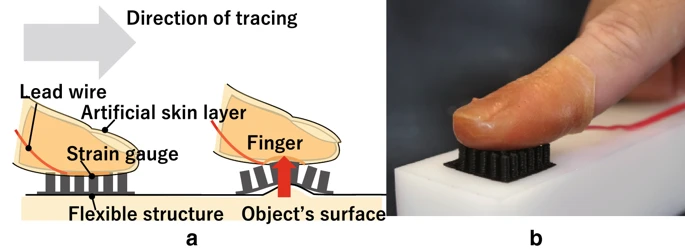
材料如橡胶和硅被用来制作传感器,应用于检测微小的波动和校准机器人手。橡胶可以用来制作一个模具,模具可以放置在手指上,模具内部装有多个应变计。手指模具和传感器可以放置在一张小橡胶片上,橡胶片上有一排橡胶针。用户可以佩戴手指模具并沿着一个表面描绘。计算机可以读取应变计的数据,测量一个或多个针是否被推起。如果有针被推起,计算机可以识别为表面存在瑕疵。这种技术在获取大面积表面瑕疵的准确数据时非常有用。[33] 另一种变体是包含相机的手指模具传感器,这些传感器将相机悬挂在硅中。硅在相机外部形成一个圆顶,硅中嵌入了等距的点标记。这些相机可以被放置在机器人手等设备上,使计算机能够接收非常准确的触觉数据。[34]
其他应用领域包括:
- 支持电影和广播的视觉效果制作,例如,相机跟踪(匹配移动)。
- 监控。
- 驾驶员疲劳检测[35][36][37]。
- 在生物科学中追踪和计数生物体[38]。
5. 典型任务
上述各个应用领域都涉及一系列计算机视觉任务;这些任务是比较明确的测量问题或处理问题,可以通过多种方法来解决。以下是一些典型计算机视觉任务的示例。
计算机视觉任务包括获取、处理、分析和理解数字图像的方法,以及从现实世界中提取高维数据,以生成数值或符号信息,例如以决策的形式。[1][2][3][4] 在这个上下文中,理解意味着将视觉图像(视网膜的输入)转化为可以与其他思维过程接口并引发适当行动的世界描述。这种图像理解可以看作是通过几何学、物理学、统计学和学习理论构建的模型,从图像数据中解开符号信息。[39]
识别
计算机视觉、图像处理和机器视觉中的经典问题是确定图像数据是否包含某个特定的物体、特征或活动。文献中描述了不同种类的识别问题。[40]
- 物体识别(也称为物体分类)——可以识别一个或多个预先指定的或学习到的物体或物体类别,通常还包括它们在图像中的 2D 位置或在场景中的 3D 姿态。Blippar、Google Goggles 和 LikeThat 提供了展示这一功能的独立程序。
- 身份识别——识别一个物体的个体实例。示例包括识别特定人的面部或指纹,识别手写数字,或识别特定的车辆。
- 检测——扫描图像数据以寻找特定物体及其位置。示例包括检测汽车视野中的障碍物,医疗图像中可能的异常细胞或组织,或自动收费系统中车辆的检测。基于相对简单和快速计算的检测有时用于寻找图像数据中较小的有趣区域,这些区域可以通过更为计算密集的技术进一步分析,以产生正确的解释。
目前,执行这些任务的最佳算法基于卷积神经网络。其能力的一个例子是 ImageNet 大规模视觉识别挑战赛;这是物体分类和检测的基准,在比赛中使用了数百万张图像和 1000 个物体类别。[41] 在 ImageNet 测试中,卷积神经网络的表现已经接近人类水平。[41] 然而,最佳算法仍然在处理小物体或细长物体时遇到困难,比如花茎上的小蚂蚁或一个人手中持有的羽毛笔。它们也难以处理经过滤镜扭曲的图像(这在现代数码相机中越来越常见)。相比之下,这类图像通常不会困扰人类。然而,人类在其他问题上往往表现不佳。例如,人类不擅长将物体分类为细粒度类别,例如特定品种的狗或鸟类物种,而卷积神经网络则能轻松处理这类任务。

基于识别的几个专门任务包括:
- 基于内容的图像检索 — 在一组较大的图像集中查找具有特定内容的所有图像。内容可以通过不同的方式进行指定,例如通过利用反向图像搜索技术,根据与目标图像的相似性来指定(给我所有与图像 X 相似的图像),或者通过给定文本输入的高层次搜索条件来指定(给我所有包含许多房屋、拍摄于冬季且没有汽车的图像)。
- 姿态估计 — 估计特定物体相对于相机的位置或方向。该技术的一个应用示例是帮助机器人臂从装配线上的输送带上取物体,或从箱子中取零件。
- 光学字符识别 (OCR) — 识别印刷或手写文本图像中的字符,通常是为了将文本编码成一种更易于编辑或索引的格式(例如 ASCII)。相关任务还包括读取二维条形码,如数据矩阵和二维码。
- 人脸识别 — 一种技术,可以将数字图像或视频帧中的人脸与人脸数据库进行匹配,目前广泛用于手机面部解锁、智能门锁等。
- 情感识别 — 人脸识别的一个子集,情感识别指的是对人类情感进行分类的过程。然而,心理学家警告称,无法可靠地从面部表情中检测出内在情感。
- 形状识别技术(SRT)— 在人数统计系统中,通过区分人类(头部和肩部的形状特征)与物体来进行识别。
- 人类活动识别 — 处理从一系列视频帧中识别活动的任务,例如判断一个人是在捡起物体还是在走路。
运动分析
- 多个任务与运动估计相关,其中图像序列被处理以估算图像中每个点或 3D 场景中的速度,甚至是产生图像的相机的运动。以下是这些任务的一些示例:
- 自运动(Egomotion)— 确定由相机拍摄的图像序列中的 3D 刚性运动(旋转和平移),即相机的运动。
- 跟踪(Tracking)— 跟踪图像序列中一组(通常是较小的)感兴趣点或物体(例如,车辆、物体、人类或其他生物)的运动。这在工业应用中广泛应用,因为大多数高运行速度的机械可以通过这种方式进行监控。
- 光流(Optical flow)— 确定图像中每个点相对于图像平面的运动,即其表观运动。这个运动是由相应的 3D 点在场景中的运动和相机相对于场景的运动共同决定的。
场景重建
给定一个或(通常是)多个场景图像,或一段视频,场景重建的目的是计算场景的 3D 模型。在最简单的情况下,模型可以是一个由 3D 点组成的集合。更复杂的方法可以生成完整的 3D 表面模型。无需运动或扫描的 3D 成像技术及相关处理算法的出现,使得该领域的快速进展成为可能。基于网格的 3D 感应可以用来从多个角度获取 3D 图像。现在已有算法能够将多个 3D 图像拼接成点云和 3D 模型。[24]
图像修复
图像修复在原始图像因外部因素(如镜头位置不当、传输干扰、低光照或运动模糊等)导致退化或损坏时变得重要,这些因素统称为噪声。当图像退化或损坏时,从中提取的信息也会受到损害。因此,我们需要恢复或修复图像,使其恢复到预期的状态。图像修复的目的是去除图像中的噪声(如传感器噪声、运动模糊等)。去噪的最简单方法是使用各种类型的滤波器,例如低通滤波器或中值滤波器。更复杂的方法则假设图像的局部结构模型,以将其与噪声区分开。通过首先分析图像数据中的局部结构,如线条或边缘,然后根据分析步骤中的局部信息来控制滤波过程,相比于更简单的方法,通常可以获得更好的去噪效果。
该领域的一个例子是修补(Inpainting)。
6. 系统方法
计算机视觉系统的组织结构高度依赖于应用。某些系统是独立的应用程序,解决特定的测量或检测问题,而其他系统则是更大设计的子系统的一部分,例如,包含用于机械驱动器控制、规划、信息数据库、人机接口等子系统。计算机视觉系统的具体实现还取决于其功能是否已预先设定,或者其某些部分是否可以在操作过程中学习或修改。许多功能是应用特有的。然而,也有一些典型的功能在许多计算机视觉系统中都有出现。
- 图像采集 – 由一个或多个图像传感器生成数字图像,这些传感器除了各种类型的光敏相机外,还包括测距传感器、断层扫描设备、雷达、超声波相机等。根据传感器的类型,生成的图像数据可能是普通的 2D 图像、3D 体积图像或图像序列。像素值通常对应于一个或多个光谱带的光强度(灰度图像或彩色图像),但也可以与各种物理量相关,例如深度、声波或电磁波的吸收或反射,或磁共振成像。[32]
- 预处理 – 在应用计算机视觉方法从图像数据中提取特定信息之前,通常需要对数据进行处理,以确保其满足方法所隐含的某些假设。例子包括:
- 重新采样以确保图像坐标系统正确。
- 降噪以确保传感器噪声不会引入虚假信息。
- 增强对比度以确保相关信息可以被检测到。
- 尺度空间表示,以增强局部适当尺度下的图像结构。
- 特征提取 – 从图像数据中提取不同复杂度级别的图像特征。[32] 常见的特征包括:
- 线条、边缘和脊线。
- 局部兴趣点,如角点、斑点或特征点。 更复杂的特征可能与纹理、形状或运动相关。
- 检测/分割 – 在处理的某个阶段,会做出关于哪些图像点或图像区域与进一步处理相关的决策。[32] 例如:
- 选择一组特定的兴趣点。
- 分割出包含特定感兴趣物体的一个或多个图像区域。
- 将图像分割成具有前景、物体组、单一物体或显著物体部分的嵌套场景结构(也称为空间分类场景层级),同时视觉显著性通常实现为空间和时间注意力。
- 对一个或多个视频进行分割或共分割,生成每帧的前景掩膜,同时保持其时间语义连续性。[46][47]
- 高级处理 – 在此步骤中,输入通常是一小组数据,例如一组点或一个图像区域,假设该区域包含特定物体。[32] 剩下的处理通常涉及:
- 验证数据是否满足基于模型和应用特定的假设。
- 估算应用特定的参数,如物体姿态或物体大小。
- 图像识别 – 将检测到的物体分类到不同的类别中。
- 图像配准 – 比较并结合同一物体的两个不同视角
- 决策制定 – 为应用程序做出最终决策,[32] 例如:
- 自动检测应用中的通过/失败。
- 识别应用中的匹配/不匹配。
- 在医学、军事、安全和识别应用中,标记需要进一步人工审查的内容。
图像理解系统
图像理解系统(IUS)包括三个抽象层次,分别如下:低层次包括图像原始元素,如边缘、纹理元素或区域;中层次包括边界、表面和体积;高层次包括物体、场景或事件。许多这些要求完全是进一步研究的课题。
在设计图像理解系统时,这些层次的表现要求包括:典型概念的表示、概念组织、空间知识、时间知识、尺度和通过比较与区分进行描述。
推理是指从当前已知的事实中推导出新的、未明确表示的事实的过程,而控制是指选择在特定处理阶段应用哪种推理、搜索和匹配技术的过程。图像理解系统的推理和控制要求包括:搜索和假设激活、匹配和假设测试、期望的生成和使用、注意力的变化和聚焦、信念的确定性和强度、推理和目标满足。[48]
7. 硬件

计算机视觉系统有很多种类;然而,所有的系统都包含以下基本元素:电源、至少一个图像采集设备(如摄像头、CCD 等)、处理器以及控制和通信电缆或某种无线互联机制。此外,实际的视觉系统还包含软件,并且通常配有显示器来监控系统的运行。用于室内空间的视觉系统,像大多数工业视觉系统,包含照明系统,并且可能被放置在受控环境中。此外,完整的系统还包括许多配件,如摄像头支架、电缆和连接器。
大多数计算机视觉系统使用可见光摄像头被动地观察场景,通常帧率为每秒 60 帧(通常要慢得多)。
少数计算机视觉系统使用带有主动照明的图像采集硬件,或者使用可见光以外的其他光源,或者两者兼有,例如结构光 3D 扫描仪、热成像摄像头、高光谱成像仪、雷达成像、激光雷达扫描仪、磁共振成像、侧扫声纳、合成孔径声纳等。这些硬件捕捉到的 “图像” 随后通常使用与处理可见光图像相同的计算机视觉算法进行处理。
虽然传统的广播和消费视频系统的工作帧率为每秒 30 帧,但数字信号处理和消费图形硬件的进步使得高速图像采集、处理和显示成为可能,能够实现每秒数百到数千帧的实时系统。在机器人应用中,快速的实时视频系统至关重要,通常能简化某些算法所需的处理。结合高速投影仪,高速图像采集可以实现 3D 测量和特征追踪。[49]
自我中心视觉系统由可穿戴摄像头组成,能够自动从第一人称视角拍摄图像。
截至 2016 年,视觉处理单元(VPU)作为一种新型处理器,正在出现并被用来补充 CPU 和图形处理单元(GPU)。[50]
8. 另见
- 棋盘检测
- 计算成像
- 计算摄影
- 计算机听觉
- 自我中心视觉
- 机器视觉术语
- 空间映射
- Teknomo–Fernandez 算法
- 视觉科学
- 视觉失认症
- 视觉感知
- 视觉系统
列表
- 计算机视觉大纲
- 新兴技术列表
- 人工智能大纲
9. 参考文献
- Reinhard Klette (2014). 《Concise Computer Vision》. Springer. ISBN 978-1-4471-6320-6.
- Linda G. Shapiro; George C. Stockman (2001). 《Computer Vision》. Prentice Hall. ISBN 978-0-13-030796-5.
- Tim Morris (2004). 《Computer Vision and Image Processing》. Palgrave Macmillan. ISBN 978-0-333-99451-1.
- Bernd Jähne; Horst Haußecker (2000). 《Computer Vision and Applications, A Guide for Students and Practitioners》. Academic Press. ISBN 978-0-13-085198-7.
- Dana H. Ballard; Christopher M. Brown (1982). 《Computer Vision》. Prentice Hall. ISBN 978-0-13-165316-0.
- Huang, T. (1996-11-19). Vandoni, Carlo E (ed.). 《Computer Vision: Evolution And Promise》 (PDF). 19th CERN School of Computing. Geneva: CERN. pp. 21–25. doi:10.5170/CERN-1996-008.21. ISBN 978-9290830955. Archived (PDF) from the original on 2018-02-07.
- Milan Sonka; Vaclav Hlavac; Roger Boyle (2008). 《Image Processing, Analysis, and Machine Vision》. Thomson. ISBN 978-0-495-08252-1.
- [http://www.bmva.org/visionoverview](http://www.bmva.org/visionoverview) Archived 2017-02-16 at the Wayback Machine The British Machine Vision Association and Society for Pattern Recognition Retrieved February 20, 2017
- Murphy, Mike (13 April 2017). "Star Trek's 'tricorder' medical scanner just got closer to becoming a reality". Archived from the original on 2 July 2017. Retrieved 18 July 2017.
- 《Computer Vision Principles, Algorithms, Applications, Learning, 5th Edition》 by E.R. Davies, Academic Press, Elsevier, 2018. ISBN 978-0-12-809284-2.
- Richard Szeliski (30 September 2010). 《Computer Vision: Algorithms and Applications》. Springer Science & Business Media. pp. 10–16. ISBN 978-1-84882-935-0.
- Sejnowski, Terrence J. (2018). 《The Deep Learning Revolution》. Cambridge, Massachusetts London, England: The MIT Press. p. 28. ISBN 978-0-262-03803-4.
- Papert, Seymour (1966-07-01). "The Summer Vision Project". MIT AI Memos (1959 - 2004). hdl:1721.1/6125.
- Margaret Ann Boden (2006). Mind as Machine: A History of Cognitive Science. Clarendon Press. p. 781. ISBN 978-0-19-954316-8.
- Takeo Kanade (6 December 2012). Three-Dimensional Machine Vision. Springer Science & Business Media. ISBN 978-1-4613-1981-8.
- Nicu Sebe; Ira Cohen; Ashutosh Garg; Thomas S. Huang (3 June 2005). Machine Learning in Computer Vision. Springer Science & Business Media. ISBN 978-1-4020-3274-5.
- William Freeman; Pietro Perona; Bernhard Scholkopf (2008). "Guest Editorial: Machine Learning for Computer Vision". International Journal of Computer Vision. 77 (1): 1. doi:10.1007/s11263-008-0127-7. hdl:21.11116/0000-0003-30FB-C. ISSN 1573-1405.
- LeCun, Yann; Bengio, Yoshua; Hinton, Geoffrey (2015). "Deep Learning" (PDF). Nature. 521 (7553): 436–444. Bibcode:2015Natur.521..436L. doi:10.1038/nature14539. PMID 26017442. S2CID 3074096.
- Jiao, Licheng; Zhang, Fan; Liu, Fang; Yang, Shuyuan; Li, Lingling; Feng, Zhixi; Qu, Rong (2019). "A Survey of Deep Learning-Based Object Detection". IEEE Access. 7: 128837–128868. arXiv:1907.09408. Bibcode:2019IEEEA...7l8837J. doi:10.1109/ACCESS.2019.2939201. S2CID 198147317.
- Ferrie, C.; Kaiser, S. (2019). Neural Networks for Babies. Sourcebooks. ISBN 978-1492671206.
- Steger, Carsten; Markus Ulrich; Christian Wiedemann (2018). Machine Vision Algorithms and Applications (2nd ed.). Weinheim: Wiley-VCH. p. 1. ISBN 978-3-527-41365-2. Archived from the original on 2023-03-15. Retrieved 2018-01-30.
- Murray, Don, and Cullen Jennings. "Stereo vision-based mapping and navigation for mobile robots Archived 2020-10-31 at the Wayback Machine." Proceedings of International Conference on Robotics and Automation. Vol. 2. IEEE, 1997.
- Andrade, Norberto Almeida. "Computational Vision and Business Intelligence in the Beauty Segment - An Analysis through Instagram" (PDF). Journal of Marketing Management. American Research Institute for Policy Development. Retrieved 11 March 2024.
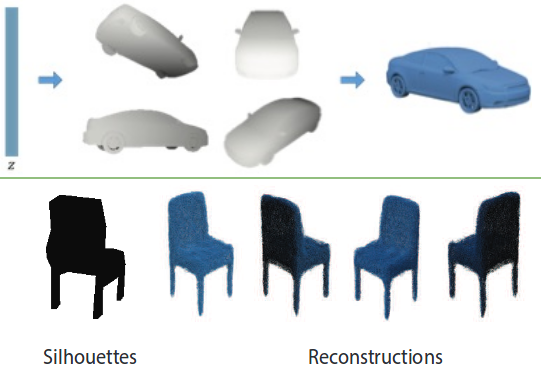
- Soltani, A. A.; Huang, H.; Wu, J.; Kulkarni, T. D.; Tenenbaum, J. B. (2017). "通过深度生成网络建模多视角深度图和轮廓合成 3D 形状". 2017 IEEE 计算机视觉与模式识别大会(CVPR)。第 1511-1519 页。doi:10.1109/CVPR.2017.269. hdl:1721.1/126644. ISBN 978-1-5386-0457-1. S2CID 31373273.
- Turek, Fred (2011 年 6 月). "机器视觉基础:如何让机器人看见". NASA 技术简报杂志. 35 (6). 第 60-62 页.
- "自动化随机箱取物的未来". 2018 年 1 月 11 日存档. 2018 年 1 月 10 日访问.
- Esteva, Andre; Chou, Katherine; Yeung, Serena; Naik, Nikhil; Madani, Ali; Mottaghi, Ali; Liu, Yun; Topol, Eric; Dean, Jeff; Socher, Richard (2021 年 1 月 8 日). "深度学习赋能的医学计算机视觉". 《npj 数字医学》. 4 (1): 5. doi:10.1038/s41746-020-00376-2. ISSN 2398-6352. PMC 7794558. PMID 33420381.
- Chervyakov, N. I.; Lyakhov, P. A.; Deryabin, M. A.; Nagornov, N. N.; Valueva, M. V.; Valuev, G. V. (2020). "基于剩余数系统的卷积神经网络硬件成本降低方案". 《神经计算》. 407: 439–453. doi:10.1016/j.neucom.2020.04.018. S2CID 219470398. 卷积神经网络(CNNs)代表了深度学习架构,目前在许多应用中得到广泛使用,包括计算机视觉、语音识别、生物信息学中白蛋白序列的识别、生产控制、金融中的时间序列分析等。
- Wäldchen, Jana; Mäder, Patrick (2017 年 1 月 7 日). "使用计算机视觉技术进行植物物种识别:系统文献综述". 《计算方法工程档案》. 25 (2): 507–543. doi:10.1007/s11831-016-9206-z. ISSN 1134-3060. PMC 6003396. PMID 29962832.
- Aghamohammadesmaeilketabforoosh, Kimia; Nikan, Soodeh; Antonini, Giorgio; Pearce, Joshua M. (2024 年 1 月). "优化草莓疾病与质量检测:结合视觉变换器与基于注意力的卷积神经网络". 《食品》. 13 (12): 1869. doi:10.3390/foods13121869. ISSN 2304-8158. PMC 11202458. PMID 38928810.
- "新 AI 模型在西方大学开发,能检测草莓疾病,旨在减少浪费"。伦敦,2024 年 9 月 13 日。检索日期:2024 年 9 月 19 日。
- E. Roy Davies (2005). 《机器视觉:理论、算法与实践》。Morgan Kaufmann. ISBN 978-0-12-206093-9.
- Ando, Mitsuhito; Takei, Toshinobu; Mochiyama, Hiromi (2020 年 3 月 3 日). "具有柔性结构的橡胶人工皮层,用于微起伏表面的形状估计". 《ROBOMECH Journal》. 7 (1): 11. doi:10.1186/s40648-020-00159-0. ISSN 2197-4225.
- Choi, Seung-hyun; Tahara, Kenji (2020 年 3 月 12 日). "多指机器人手通过视觉-触觉指尖传感器进行灵巧物体操作". 《ROBOMECH Journal》. 7 (1): 14. doi:10.1186/s40648-020-00162-5. ISSN 2197-4225.
- Garg, Hitendra (2020 年 2 月 29 日). "使用传统计算机视觉应用检测驾驶员困倦". 2020 年国际可再生能源与控制中电力电子与物联网应用会议(PARC)。第 50-53 页。doi:10.1109/PARC49193.2020.236556. ISBN 978-1-7281-6575-2. S2CID 218564267. 2022 年 6 月 27 日存档,2022 年 11 月 6 日访问。
- Hasan, Fudail; Kashevnik, Alexey (2021 年 5 月 14 日). "基于计算机视觉的现代困倦检测算法的最新分析". 2021 年第 29 届开放创新协会会议(FRUCT)。第 141-149 页。doi:10.23919/FRUCT52173.2021.9435480. ISBN 978-952-69244-5-8. S2CID 235207036. 2022 年 6 月 27 日存档,2022 年 11 月 6 日访问。
- Balasundaram, A; Ashokkumar, S; Kothandaraman, D; Kora, SeenaNaik; Sudarshan, E; Harshaverdhan, A (2020 年 12 月 1 日). "基于计算机视觉的面部参数疲劳检测". 《IOP 会议系列:材料科学与工程》. 981 (2): 022005. Bibcode:2020MS&E..981b2005B. doi:10.1088/1757-899X/981/2/022005. ISSN 1757-899X. S2CID 230639179.
- Bruijning, Marjolein; Visser, Marco D.; Hallmann, Caspar A.; Jongejans, Eelke; Golding, Nick (2018). "trackdem: 自动化粒子追踪,通过 R 中的视频获得种群计数和大小分布". 《生态学与进化方法》. 9 (4): 965–973. Bibcode:2018MEcEv...9..965B. doi:10.1111/2041-210X.12975. hdl:2066/184075. ISSN 2041-210X.
- David A. Forsyth; Jean Ponce (2003). 《计算机视觉:现代方法》。Prentice Hall. ISBN 978-0-13-085198-7.
- Forsyth, David; Ponce, Jean (2012). 《计算机视觉:现代方法》。Pearson.
- Russakovsky, Olga; Deng, Jia; Su, Hao; Krause, Jonathan; Satheesh, Sanjeev; Ma, Sean; Huang, Zhiheng; Karpathy, Andrej; Khosla, Aditya; Bernstein, Michael; Berg, Alexander C. (2015 年 12 月). "ImageNet 大规模视觉识别挑战". 《国际计算机视觉期刊》. 115 (3): 211–252. arXiv:1409.0575. doi:10.1007/s11263-015-0816-y. hdl:1721.1/104944. ISSN 0920-5691. S2CID 2930547. 2023 年 3 月 15 日存档,2020 年 11 月 20 日访问。
- Quinn, Arthur (2022 年 10 月 9 日). "AI 图像识别:现代生活方式的不可避免趋势". TopTen.ai. 2022 年 12 月 2 日存档,2022 年 12 月 23 日访问。
- Barrett, Lisa Feldman; Adolphs, Ralph; Marsella, Stacy; Martinez, Aleix M.; Pollak, Seth D. (2019 年 7 月). "重新审视情感表达:从人类面部运动推断情感的挑战". 《公共心理科学》. 20 (1): 1–68. doi:10.1177/1529100619832930. ISSN 1529-1006. PMC 6640856. PMID 31313636.
- A. Maity (2015). "改进的显著物体检测与操作". arXiv:1511.02999 [cs.CV].
- Barghout, Lauren. "使用模糊空间分类法的图像分割的视觉分类方法,得出具有情境相关区域的分类"。《信息处理与知识系统中的不确定性管理》. Springer 国际出版,2014 年。
- Liu, Ziyi; Wang, Le; Hua, Gang; Zhang, Qilin; Niu, Zhenxing; Wu, Ying; Zheng, Nanning (2018). "通过耦合动态马尔科夫网络进行视频物体发现与分割" (PDF). 《IEEE 图像处理学报》. 27 (12): 5840–5853. Bibcode:2018ITIP...27.5840L. doi:10.1109/tip.2018.2859622. ISSN 1057-7149. PMID 30059300. S2CID 51867241. 2018 年 9 月 7 日存档,2018 年 9 月 14 日访问。
- Wang, Le; Duan, Xuhuan; Zhang, Qilin; Niu, Zhenxing; Hua, Gang; Zheng, Nanning (2018 年 5 月 22 日). "Segment-Tube: 在未裁剪视频中进行时空动作定位和逐帧分割" (PDF). 《传感器》. 18 (5): 1657. Bibcode:2018Senso..18.1657W. doi:10.3390/s18051657. ISSN 1424-8220. PMC 5982167. PMID 29789447. 2018 年 9 月 7 日存档。
- Shapiro, Stuart C. (1992). 《人工智能百科全书》第 1 卷. 纽约: John Wiley & Sons, Inc. 第 643-646 页. ISBN 978-0-471-50306-4.
- Kagami, Shingo (2010). "用于实时感知世界的高速视觉系统和投影仪". 2010 年 IEEE 计算机学会计算机视觉与模式识别研讨会. 第 2010 卷,第 100-107 页. doi:10.1109/CVPRW.2010.5543776. ISBN 978-1-4244-7029-7. S2CID 14111100.
- Seth Colaner (2016 年 1 月 3 日). "VR/AR 的第三种处理器类型:Movidius 的 Myriad 2 VPU". www.tomshardware.com. 2023 年 3 月 15 日存档,2016 年 5 月 3 日访问。
10. 进一步阅读
- James E. Dobson (2023). 《计算机视觉的诞生》. 明尼苏达大学出版社. ISBN 978-1-5179-1421-9.
- David Marr (1982). 《视觉》. W. H. Freeman and Company. ISBN 978-0-7167-1284-8.
- Azriel Rosenfeld; Avinash Kak (1982). 《数字图像处理》. 学术出版社. ISBN 978-0-12-597301-4.
- Barghout, Lauren; Lawrence W. Lee (2003). 《感知信息处理系统》. 美国专利申请 10/618,543. ISBN 978-0-262-08159-7.
- Berthold K.P. Horn (1986). 《机器人视觉》. MIT 出版社. ISBN 978-0-262-08159-7.
- Michael C. Fairhurst (1988). 《机器人系统的计算机视觉》. Prentice Hall. ISBN 978-0-13-166919-2.
- Olivier Faugeras (1993). 《三维计算机视觉:几何观点》. MIT 出版社. ISBN 978-0-262-06158-2.
- Tony Lindeberg (1994). 《计算机视觉中的尺度空间理论》. Springer. ISBN 978-0-7923-9418-1.
- James L. Crowley; Henrik I. Christensen, eds. (1995). 《视觉作为过程》. Springer-Verlag. ISBN 978-3-540-58143-7.
- Gösta H. Granlund; Hans Knutsson (1995). 《计算机视觉的信号处理》. Kluwer 学术出版社. ISBN 978-0-7923-9530-0.
- Reinhard Klette; Karsten Schluens; Andreas Koschan (1998). 《计算机视觉——来自图像的三维数据》. Springer,新加坡. ISBN 978-981-3083-71-4.
- Emanuele Trucco; Alessandro Verri (1998). 《三维计算机视觉入门技术》. Prentice Hall. ISBN 978-0-13-261108-4.
- Bernd Jähne (2002). 《数字图像处理》. Springer. ISBN 978-3-540-67754-3.
- Richard Hartley and Andrew Zisserman (2003). 《计算机视觉中的多视角几何学》. 剑桥大学出版社. ISBN 978-0-521-54051-3.
- Gérard Medioni; Sing Bing Kang (2004). 《计算机视觉中的新兴话题》. Prentice Hall. ISBN 978-0-13-101366-7.
- R. Fisher; K Dawson-Howe; A. Fitzgibbon; C. Robertson; E. Trucco (2005). 《计算机视觉与图像处理词典》. 约翰·威利出版社. ISBN 978-0-470-01526-1.
- Nikos Paragios 和 Yunmei Chen 和 Olivier Faugeras (2005). 《计算机视觉中的数学模型手册》. Springer. ISBN 978-0-387-26371-7.
- Wilhelm Burger; Mark J. Burge (2007). 《数字图像处理:使用 Java 的算法方法》. Springer. ISBN 978-1-84628-379-6. 2014 年 5 月 17 日存档,2007 年 6 月 13 日访问。
- Pedram Azad; Tilo Gockel; Rüdiger Dillmann (2008). 《计算机视觉——原理与实践》. Elektor 国际媒体公司. ISBN 978-0-905705-71-2.
- Richard Szeliski (2010). 《计算机视觉:算法与应用》. Springer-Verlag. ISBN 978-1848829343.
- J. R. Parker (2011). 《图像处理与计算机视觉的算法(第二版)》. Wiley. ISBN 978-0470643853.
- Richard J. Radke (2013). 《计算机视觉与视觉效果》. 剑桥大学出版社. ISBN 978-0-521-76687-6.
- Nixon, Mark; Aguado, Alberto (2019). 《计算机视觉的特征提取与图像处理(第四版)》. 学术出版社. ISBN 978-0128149768.
11. 外部链接
- USC Iris 计算机视觉会议列表
- 计算机视觉论文网络 – 一份完整的计算机视觉会议论文列表。
- 计算机视觉在线 2011 年 11 月 30 日存档于 Wayback Machine – 与计算机视觉相关的新闻、源代码、数据集和职位信息。
- CVonline – Bob Fisher 的计算机视觉大全。
- 英国机器视觉协会 – 通过 BMVC 和 MIUA 会议、BMVA 年刊(开放源期刊)、BMVA 夏季学校和一日会议支持英国的计算机视觉研究。
- 计算机视觉容器,Joe Hoeller GitHub:广泛采用的开源容器,用于 GPU 加速的计算机视觉应用。被研究人员、大学、私营公司以及美国政府广泛使用。