BERT
编辑BERT是一种语言表示模型,BERT代表来自Transformer的双向编码器表示(Bidirectional Encoder Representations from Transformers)。BERT旨在通过联合调节所有层中的左右上下文来预训练深度双向表示。因此,只需要一个额外的输出层,就可以对预训练的BERT表示进行微调,从而为广泛的任务(比如回答问题和语言推断任务)创建最先进的模型,而无需对特定于任务进行大量模型结构的修改。
BERT的概念很简单,但实验效果很强大,截至2018年10月刷新了 11 个NLP任务的当前最优结果,是NLP领域一个突破性进展。[1]
1 背景编辑
语言模型预训练可以显著提高许多自然语言处理任务的效果,现有的两种方法可以将预训练好的语言模型表示应用到下游任务中:基于特征的方法和微调方法。基于特征的方法比如 ELMo,提取某层或多层特征用于下游任务。而微调方法,如生成预训练 Transformer (OpenAI GPT) 模型,然后引入最小的特定于任务的参数,并通过简单地微调预训练模型的参数对下游任务进行训练。微调方法过去主要的局限性是标准语言模型是单向的,这就限制了可以在预训练期间可以使用的模型结构的选择。通过提出 BERT 改进了基于微调的方法:来自Transformer 的双向编码器表示。BERT、OpenAI GPT 和 ELMo 之间的比较如图所示。
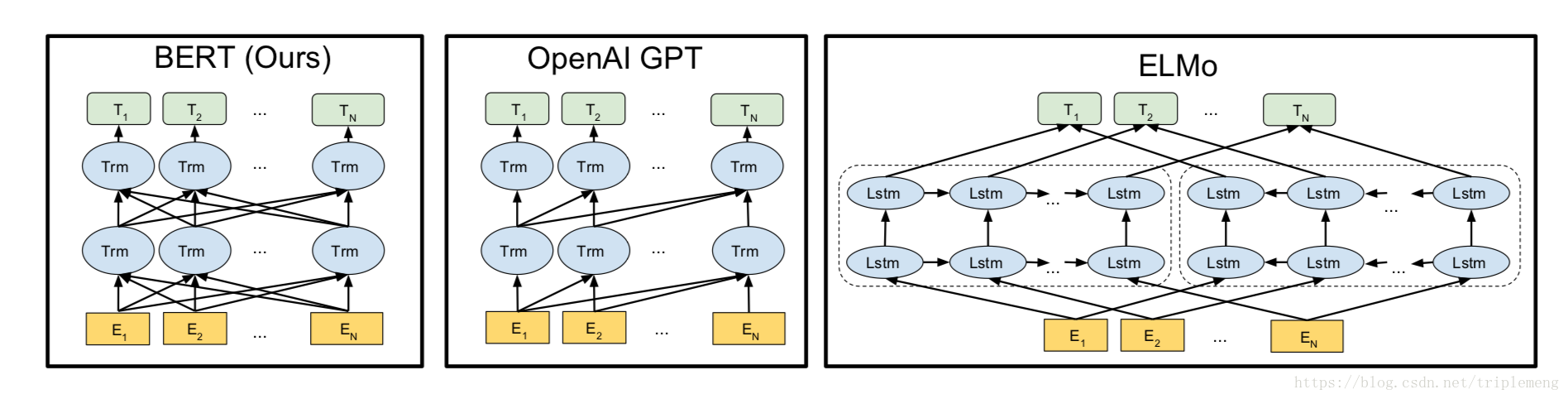
2 模型编辑
BERT 的模型结构是一个多层双向 Transformer 编码器。
2.1 输入表示
输入表示能够在一个标记序列中清楚地表示单个文本句子或一对文本句子,输入嵌入是标记嵌入(词嵌入)、
句子嵌入和位置嵌入的总和。
Token embeddings:词嵌入/词向量。
Segment embeddings:句子嵌入,用来标记不同的两个句子。
Positional embeddings:位置嵌入,将 positional embedding 添加到每个 token 中,以标示其在句子中的位置,通过模型学习出来。
2.2 任务一:遮蔽语言模型
为了训练深度双向表示,采用了一种简单的方法,即随机遮蔽一定比例的输入标记,然后仅预测那些被遮蔽的标记。我们将这个过程称为“遮蔽语言模型”(MLM)。在每个序列中随机遮蔽 15% 的标记。
数据生成不会总是用 [MASK] 替换被选择的单词,而是执行以下操作:
80% 的情况下:用 [MASK] 替换被选择的单词,例如,my dog is hairy → my dog is [MASK]
10% 的情况下:用一个随机单词替换被选择的单词,例如,my dog is hairy → my dog is apple
10% 的情况下:保持被选择的单词不变,例如,my dog is hairy → my dog is hairy。这样做的目的是使表示偏向于实际观察到的词。
Transformer 编码器不知道它将被要求预测哪些单词,或者哪些单词已经被随机单词替换,因此它被迫保持每个输入标记的分布的上下文表示。另外,因为随机替换只发生在 1.5% 的标记(即,15% 的10%)这似乎不会损害模型的语言理解能力。
2.3 任务二:下一句预测
许多重要的下游任务,如问题回答(QA)和自然语言推理(NLI),都是建立在理解两个文本句子之间的关系的基础上的,而这并不是语言建模直接捕捉到的。为了训练一个理解句子关系的模型,预训练了一个下一句预测的二元分类任务,这个任务可以从任何单语语料库中简单地归纳出来,预测输入BERT的两端文本是否为连续的文本。具体来说,在为每个训练前的例子选择句子 A 和 B 时,50% 的情况下 B 是真的在 A 后面的下一个句子,50% 的情况下是来自语料库的随机句子。
2.4 预训练过程
预训练过程大体上遵循语言模型预训练过程。
2.5 微调过程
对于序列级别的分类任务,BERT 微调非常简单。为了获得输入序列的固定维度的表示,我们取特殊标记
([CLS])构造相关的嵌入对应的最终的隐藏状态(即,为 Transformer 的输出)的池化后输出。对于区间级和标记级预测任务,必须以特定于任务的方式稍微修改上述过程。对于微调,除了批量大小、学习率和训练次数外,大多数模型超参数与预训练期间相同。BERT将传统大量在下游具体NLP任务中做的操作转移到预训练词向量中,在获得使用BERT词向量后,最终只需在词向量上加简单的MLP或线性分类器即可,论文中所给的几类任务:句子关系判断、分类任务、序列标注、命名体识别如图所示。3 关键创新编辑
引入了Masked LM,使用双向LM做模型预训练,能够获取上下文相关的双向特征表示,是BERT的最大亮点。[2]
为下游任务引入了很通用的求解框架,不再为任务做模型定制。
微调成本低。
4 实验结果编辑
BERT是截至2018年10月的最新state of the art模型,当时刷新的11项自然语言处理任务的最新记录包括:将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%),将SQuAD v1.1问答测试F1得分纪录刷新为93.2分(绝对提升1.5分),超过人类表现2.0分
5 变体编辑
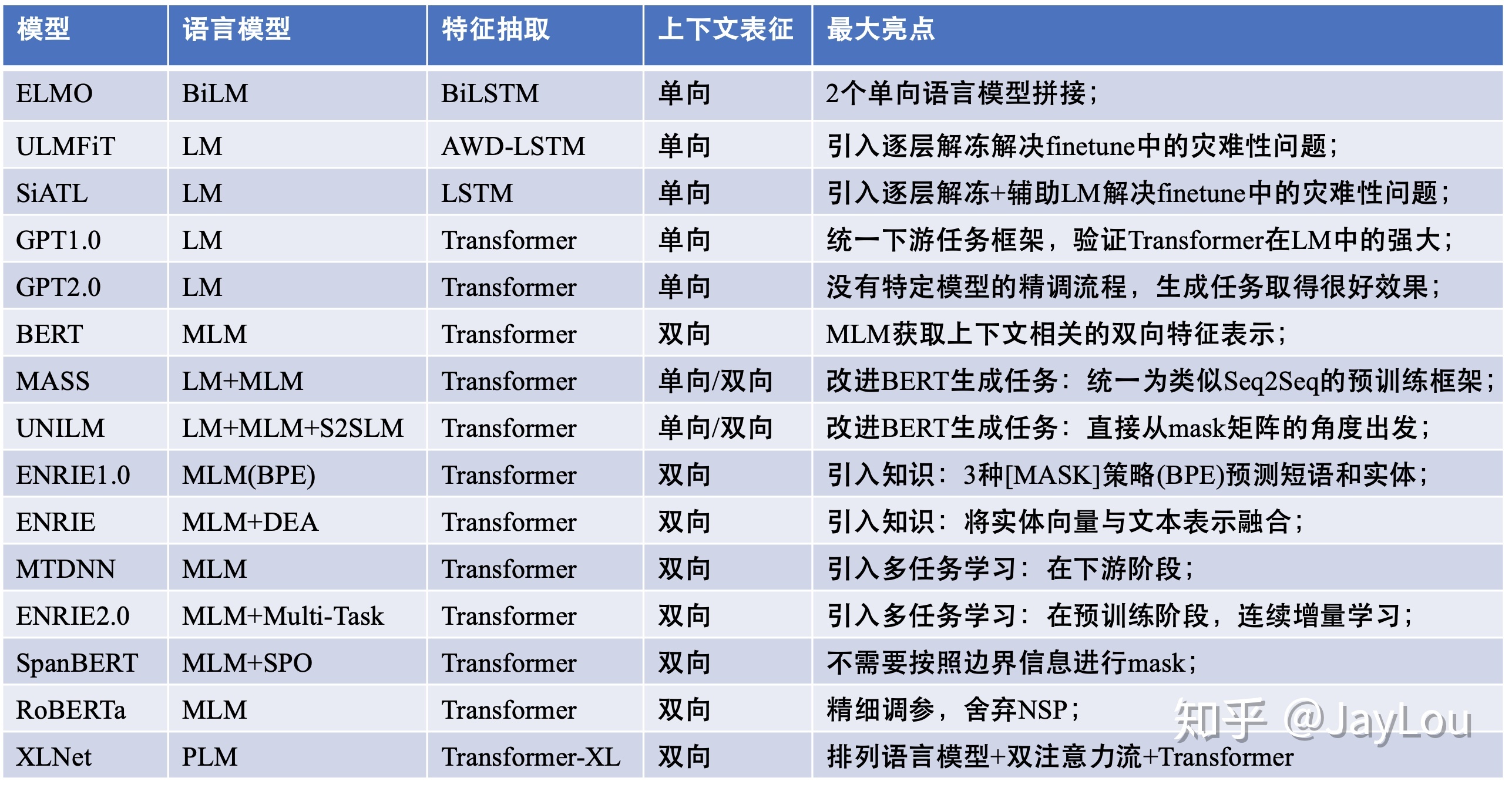
bert自从横空出世以来,引起广泛关注,相关研究及bert变体/扩展喷涌而出,如蒸馏的DistilBERT、改进MASK的SpanBERT、精细调参的RoBERTa、改进生成任务方向的MASS、UNILM、以及引入知识的ERNIE、引入多任务的ERNIE2.0等。
参考文献
暂无