决策树
编辑决策论中 (如风险管理),决策树(Decision tree)由一个决策图和可能的结果(包括资源成本和风险)组成, 用来创建到达目标的规划。决策树建立并用来辅助决策,是一种特殊的树结构。决策树是一个利用像树一样的图形或决策模型的决策支持工具,包括随机事件结果,资源代价和实用性。它是一个算法显示的方法。决策树经常在运筹学中使用,特别是在决策分析中,它帮助确定一个能最可能达到目标的策略。如果在实际中,决策不得不在没有完备知识的情况下被在线采用,一个决策树应该平行概率模型作为最佳的选择模型或在线选择模型算法。决策树的另一个使用是作为计算条件概率的描述性手段。
1 概观编辑
决策树是一种类似流程图的结构,其中每个内部节点代表一个属性的“测试”(例如硬币翻转出现正面朝上或反面朝上),每个分支代表测试的结果,每个叶节点代表一个类标签(在计算所有属性后做出的决策)。从根到叶的路径代表分类规则。
在决策分析中,决策树和密切相关的影响图被用作可视化和分析性的决策支持工具,使用该工具计算备选方案的期望值(或预期效用)。
决策树由三种类型的节点组成:[1]
- 决策节点——通常由正方形表示
- 机会节点——通常用圆圈表示
- 结束节点–通常由三角形表示
决策树通常用于运筹学和运营管理。在实践中,如果必须在不完全了解的情况下在线不召回地做出决策,决策树应该与概率模型一同作为最佳选择模型或在线选择模型的算法。决策树的另一个用途是作为计算条件概率的手段。
决策树、影响图、效用函数和其他决策分析工具会被作为运筹学或管理学的例子,被教授给商学院、卫生经济学和公共卫生学院的本科生。
2 决策树构件编辑
2.1 决策树元素
决策树从左到右绘制,只有突发节点(分割路径),没有汇聚节点(汇聚路径)。因此,手动绘制时,它们会变得非常大,通常我们很难用手完全画出来。传统上,决策树是手动创建的——正如上图的例子所示——但是现在绘制决策树越来越多地使用专门的软件。
2.2 决策规则
决策树可以线性化理解为决策规则[2],结果是叶节点的内容,路径上的条件在if子句中形成一个连接。一般来说,规则有以下形式:
if条件1、条件2和条件3,then结果。
决策规则可以通过用目标变量构造关联规则来生成。决策规则也可以表示时间或因果关系。[3]
2.3 决策树使用流程图符号
通常使用流程图符号绘制决策树,因为这样对大多数人来说更容易阅读和接受。
2.4 分析示例
分析可以考虑决策者的(例如公司的)偏好或效用函数,例如:
这种情况下的基本解释是,在现实风险偏好系数下,公司更偏好b股的风险和收益。(超过40万美元: 在该风险规避范围内,公司需要建立第三种策略,即“A和B方案都不用”)
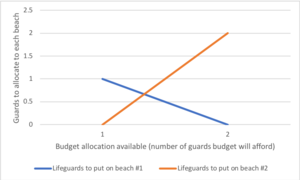
运筹学课程中常用的另一个例子是海滩救生员的分布( 也叫作“生命海滩”)。[4]这个例子描述了两个海滩,在每个海滩上都有救生员,两个海滩之间(总计)可以分配救生员的最大预算,分析师使用边际收益表,可以决定分配给每个海滩多少救生员。
| 每个海滩上都有救生员 | 海滩#1,共防止溺水 | 海滩#2,共防止溺水 |
|---|---|---|
| 1 | 1 | 3 |
| 2 | 4 | 0 |
在这个例子中,可以画一棵决策树来说明海滩#2收益递减的原理。
决策树显示,当按顺序分配救生员时,如果只有一名救生员,那么在1号海滩部署救生员将是最佳选择。但是如果有两个救生员的预算,那么把他们都放在2号海滩会防止更多的溺水事件。
2.5 影响图
决策树中的许多信息可以更简洁地表示为影响图,即关注于事件之间的问题和关系上。
3 关联规则归纳编辑
决策树也可以视为经验数据归纳规则下的生成模型。通常,最优决策树是一个考虑到大部分数据同时最小化级别(或“问题”)数量的树。[5]目前已经设计了几种生成最优决策树的算法,例如ID3/4/5、[5] CLS、ASSISTANT和CART。
4 优点和缺点编辑
在决策支持工具中,决策树(和影响图)有几个优点。决策树:
- 易于理解和解释。经过简单的解释,人们能够理解决策树模型。
- 即使只有很少的硬性数据也有价值。重要的见解可以基于专家描述(它的替代方案、概率和成本)和他们对结果的偏好而产生。
- 帮助确定不同场景的最坏和最好的预期值。
- 使用白盒模型。如果模型提供了已知结果。
- 可以与其他决策技术相结合。
决策树的缺点:
- 决策树是不稳定的,这意味着微小的数据变化会导致最优决策树结构的巨大变化。
- 它们通常相对不准确。可能许多其他预测因子在相似的数据下表现更好。虽然这可以通过用决策树的随机森林替换单个决策树来补救,但是随机森林不像单个决策树那样容易解释。
- 对于包含具有不同级别的分类变量的数据,决策树中的信息增益偏向于具有更多级别的属性。[6]
- 当许多值不确定或许多结果相关时,计算可能会变得非常复杂。
参考文献
- [1]
^Kamiński, B.; Jakubczyk, M.; Szufel, P. (2017). "A framework for sensitivity analysis of decision trees". Central European Journal of Operations Research. 26 (1): 135–159. doi:10.1007/s10100-017-0479-6. PMC 5767274. PMID 29375266..
- [2]
^Quinlan, J. R. (1987). "Simplifying decision trees". International Journal of Man-Machine Studies. 27 (3): 221–234. CiteSeerX 10.1.1.18.4267. doi:10.1016/S0020-7373(87)80053-6..
- [3]
^K. Karimi and H.J. Hamilton (2011), "Generation and Interpretation of Temporal Decision Rules", International Journal of Computer Information Systems and Industrial Management Applications, Volume 3.
- [4]
^Wagner, Harvey M. (1975-09-01). Principles of Operations Research: With Applications to Managerial Decisions (in English) (2nd ed.). Englewood Cliffs, NJ: Prentice Hall. ISBN 9780137095926.CS1 maint: Unrecognized language (link).
- [5]
^Utgoff, P. E. (1989). Incremental induction of decision trees. Machine learning, 4(2), 161-186. doi:10.1023/A:1022699900025.
- [6]
^Deng,H.; Runger, G.; Tuv, E. (2011). Bias of importance measures for multi-valued attributes and solutions (PDF). Proceedings of the 21st International Conference on Artificial Neural Networks (ICANN)..
暂无