tomasulo算法
编辑Tomasulo算法是一种用于指令动态调度的计算机体系结构硬件算法,它允许无序执行,并能够更有效地使用多个执行单元。它由IBM的罗伯特·托马苏洛(Robert Tomasulo)于1967开发,并首次在IBM System/360 Model 91的浮点单元中实现。
托马苏洛算法的主要创新包括硬件中的寄存器重命名、所有执行单元的保留站以及公共数据总线(CDB),在公共数据总线上,计算值广播到所有可能需要它们的保留站。这些发展允许改进指令的并行执行,否则在使用记分板或其他早期算法时,这些指令会停止。
罗伯特·托马苏洛因其在算法方面的工作于1997年获得埃克特-莫齐利奖。[1]
目录编辑
1 实施概念编辑
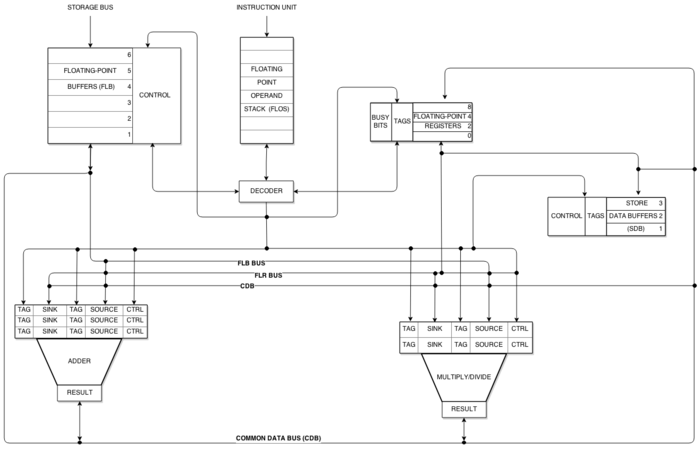
以下是实施托马苏洛算法所必需的概念:
1.1 公共数据总线
公共数据总线(CDB)将保留站直接连接到功能单元。托马苏洛认为,它“在鼓励并发的同时保持优先级”。 这有两个重要影响:
1、功能单元可以在不涉及浮点寄存器的情况下访问任何操作的结果,从而允许等待结果的多个单元继续进行,而无需等待解决对寄存器文件读取端口的访问争用。
2、危险检测和控制执行是分布式的。保留站控制指令何时可以执行,而不是单个专用的危险单元去控制。
1.2 指令顺序
指令按顺序发布,因此指令序列的效果(例如由这些指令引发的异常)与它们在有序处理器上的效果按照相同的顺序发生,而不管它们是无序(即非顺序)执行的事实。
1.3 寄存器重命名
托马苏洛算法使用寄存器重命名来正确执行无序执行。所有通用寄存器和保留站寄存器要么保存一个实值,要么保存一个占位符值。如果实际值在发布阶段对目标寄存器不可用,则最初使用占位符值。占位符值是指示哪个保留站将产生真实值的标签。当设备完成并在CDB广播结果时,占位符将被替换为真实值。
每个功能单元都有一个保留站。保留站保存执行单个指令所需的信息,包括操作和操作数。当它空闲时,以及一条指令所需的所有源操作数都为真实值时,功能单元开始处理。
1.4 例外
实际上,有些异常可能没有足够的异常状态信息,在这种情况下,处理器可能会引发一个特殊的异常,称为“不精确”异常。非OoOE实现中不能出现不精确的异常,因为处理器状态只按程序顺序改变(参见RISC流水线异常)。
经历“精确”异常的程序可以在异常点重新启动或重新执行,同时可以确定引起异常的特定指令。然而,那些经历“不精确”异常的程序通常不能重启或重新执行,因为系统不能确定引起异常的特定指令。
2 指令生命周期编辑
下面列出的三个阶段是每个指令从发出到执行完成所经过的阶段。
2.1 注册图例
- Op -表示对操作数执行的操作
- Qj,Qk -将产生相关源操作数的保留站(0表示值为Vj,Vk)
- Vj,Vk -源操作数的值
- A -用于保存加载或存储的内存地址信息
- Busy - 1(如果已占用),0(如果未占用)
- Qi -(仅寄存器单元)其结果应存储在该寄存器中的保留站(如果为空或0,则没有值指定给该寄存器)
2.2 第一阶段:问题
在发布阶段,如果所有操作数和保留站都准备好了,或者它们被停止,则发布指令以供执行。在此步骤中,寄存器被重命名,消除了WAR和WAW危险。
- 从指令队列的头部检索下一条指令。如果指令操作数当前在寄存器中,则
- 如果有匹配的功能单元,发出指令。
- 否则,由于没有可用的功能单元,暂停指令,直到一个站或缓冲器空闲。
- 否则,我们可以假设操作数不在寄存器中,因此使用虚拟值。功能单元必须计算实值,以跟踪产生操作数的功能单元。
| Instruction state | Wait until | Action or bookkeeping |
|---|---|---|
| Issue | Station r empty | |
| Load or Store | Buffer r empty | |
| Load only | |
|
| Store only | |
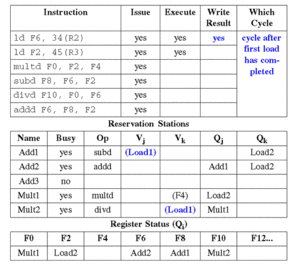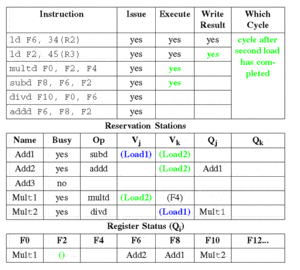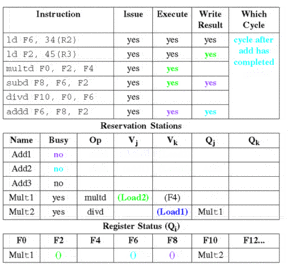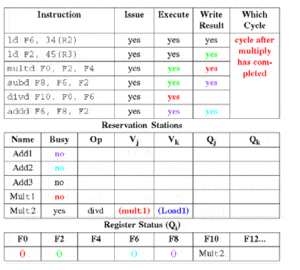
2.3 阶段2:执行
在执行阶段,执行指令操作。在这个步骤中,指令被延迟,直到它们的所有操作数都可用,消除了RAW危险。通过有效的地址计算来保持程序的正确性,以防止内存中的危险。
- 如果一个或多个操作数尚不可用,则:等待操作数在CDB上可用。
- 当所有操作数都可用时,那么:如果指令是加载或存储
- 当基本寄存器可用时,计算有效地址,并将其放入加载/存储缓冲区
- 如果指令是加载指令,那么:一旦内存单元可用,就执行
- 否则,如果指令是一个存储指令,那么:在将该值发送到内存单元之前,等待该值被存储
- 当基本寄存器可用时,计算有效地址,并将其放入加载/存储缓冲区
- 否则,该指令是算术逻辑单元操作,然后:在相应的功能单元执行该指令
| Instruction state | Wait until | Action or bookkeeping |
|---|---|---|
| FP operation | |
Compute result: operands are in Vj and Vk |
| Load/store step 1 | RS[r].Qj = 0 & r is head of load-store queue |
|
| Load step 2 | Load step 1 complete | Read from |
2.4 阶段3:写结果
在写结果阶段,算术逻辑单元操作结果被写回寄存器,存储操作被写回内存。
- 如果指令是算术逻辑单元操作
- 如果结果是可用的,那么:把它写在CDB,然后从那里写入寄存器和任何等待这个结果的保留站
- 否则,如果指令是一个存储指令,那么:在这个步骤中将数据写入内存
| Instruction state | Wait until | Action or bookkeeping |
|---|---|---|
| FP operation or load | Execution complete at r & CDB available | |
| Store | Execution complete at r & RS[r].Qk = 0 | |
3 算法改进编辑
托马苏洛算法中的保留站、寄存器重命名和公共数据总线的概念为高性能计算机的设计带来了显著的进步。
保留站负责在存在数据依赖性和其他不一致(如改变存储访问时间和电路速度)的情况下等待操作数,从而释放功能单元。这种改进克服了长浮点延迟和访问内存。特别是,该算法对缓存未命中的容忍度更高。此外,程序员不用实现优化的代码。这是公共数据总线和保留站共同努力,以保持依赖性以及鼓励并发性的结果。[2]
通过跟踪保留站中指令的操作数和硬件中的寄存器重命名,该算法最小化了写后读(RAW),消除了写后写(WAW)和读后写(WAR)计算机体系结构的危险。这通过减少等待所需的浪费时间来提高性能。[2]
算法中同样重要的改进是设计不限于特定的管道结构。这种改进使得该算法被多版本处理器更广泛地采用。此外,该算法易于扩展以支持分支推测。[2]
4 应用程序和遗留编辑
参考文献
- [1]
^"Robert Tomasulo – Award Winner". ACM Awards. ACM. Retrieved 8 December 2014..
- [2]
^Tomasulo, Robert Marco (Jan 1967). "An Efficient Algorithm for Exploiting Multiple Arithmetic Units". IBM Journal of Research and Development. IBM. 11 (1): 25–33. doi:10.1147/rd.111.0025. ISSN 0018-8646..
- [3]
^Yoga, Adarsh. "Differences between Tomasulo's algorithm and dynamic scheduling in Intel Core microarchitecture". The boozier. Retrieved 4 April 2016..
暂无